
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- branch
- 그리디
- Github
- map
- Next
- string
- ccw 알고리즘
- localstorage
- ERD
- insomnia
- trie
- Prisma
- html5
- vector insert
- Keys
- PROJECT
- 트라이
- MySQL
- Express.js
- router
- HTTP
- 그래프 탐색
- DP
- 자바스크립트
- 백준 1918번
- JavaScript
- MongoDB
- 게임 서버 아키텍처
- 이분 탐색
- pm2
- Today
- Total
dh_0e
[Database] SQL I, II (3, 5장) 본문
Database Languages functionality categrized into (기능적 분류)
- DDL(data definition language) - 스키마 관련 언어
- DML(data manipulation language) - 데이터(인스턴스) 관련 언어
- DCL(data control language) - 부가적 관리 언어
DBL expressed categorized into (표현되는 방식 관점)
- Procedural - 절차적
- Non-procedural (declarative) - 비절차적
DDL(data definition language)
- Specification for defining the database schema - 스키마에 대한 조작을 담당
- Specification for the domains with each attribute, integrity constraints - 스키마에 관련된 도메인, 무결성 제약 조건 등을 표현하는 기능 제공
- DDL compiler generates a set of tables, which are stored in a data dictionary - 스키마에 대한 정보를 데이터 사전에 저장/관리
- 스키마 생성, 삭제, 변경 등을 담당
DML(data manipulation language)
- Language for accessing and manipulating the data(instances)
- Retrieve/insert/delete/update - DB 데이터(인스턴스)의 조회/삽입/삭제/변경 등의 기능을 사용자에게 제공
- Also called a query language - 사용자는 DML을 이용하여 질의를 생성하여 DB 시스템에 전달/처리하므로 질의어라고도 함
DCL(data control language)
DCL include
- Transaction start/end - 트랜잭션 시작/종료
- Session start/end - 세션 시작/종료
- Backup/recovery - 회복 및 복구 기능
- Authorization grant/revoke - 권한 부여/취소
- User account management - 사용자 계정 관리
책마다 DB언어를 DCL을 제외하고 DDL, DML 2개로 분류하기도 함
Procedural(절차적) vs. Declarative(비절차적)
- Procedural L. 는 처리 방법 및 절차(how to do)를 명시하고, Declarative L. 는 방법 및 절차에 대한 언급 없이 원하는 데이터(what to do)만을 명시
- SQL 언어는 Declarative 언어이며, 사용자는 원하는 데이터를 선언적으로 표현할 뿐 How to do는 명시하지 않음
- Declarative L.가 Procedural L. 보다 more advanced(진보된) 언어지만 컴퓨터 시스템 관점에서는 process 하기 어렵고 복잡함
SQL(structured query language)
- 구조화된 쿼리 언어
- Relational database language that has functionalities of DDL, DML, DCL - DDL, DML, DCL을 모두 포함하는 관계형 DB 언어
- IBM first developed as part of System R(mid 70s)
Standard Organizations
- ISO (International Standard Organization) - UN의 산하 기관의로 DB 분야 외에도 정보통신 분야에서 다양한 표준안을 제정하고 있으며 가장 인정받는 기관
- ANSI (American National Standards Institute) - 미국 표준화 공인 기관, ISO의 표준 제정에 많은 영향력을 발휘
- W3C (World Wide Web Consortium) - 인터넷 관련 기술 표준을 제정
- OMG (Object Management Group)
- Open Group
DDL(Data Definition Language) SQL
- Allows the specification of not only a set of relations but also information about each relations - 아래와 같이 관계 및 이와 관련된 정보를 정의하는 기능을 제공
- The schema for each relation (관계 스키마)
- The domain of values associated with each attribute (속성의 도메인)
- Integrity constraints (무결성 제약)
- The set of indices to be maintained (관계와 연관되는 인덱스 집합)
- The physical storage structure of relation (관계 저장을 위한 디스크 상의 물리적 구조)
- Security and authorization (관계와 연관되는 보안 및 권한 부여/취소) - 일부 문헌에서는 DCL로 분류하기도 함
- 대소문자 구분이 없으며 인용부호(',") 내에서만 구분
- 세미콜론을 SQL 문장의 끝을 표기하며, 일부 상용 DBMS에서는 요구하지 않기도 함
Domain types in SQL
- char(n): Fixed-length character string with length n
- varchar(n): Variable-length character string with maximum length n
- int: Integer
- smallint: Small integer
- numeric(p, d): Fixed point number with precision of p digits, with d digits to the right of decimal point - p는 유효숫자 개수, d는 소수점 다음에 나오는 숫자 개수 ex) numberic(5,2)는 xxx.xx 형태
DDL SQL
DDL has three key words: CREATE, DROP, ALTER
Create table R
- R이라는 새로운 테이블을 정의하여 생성, 뒤에 속성명과 도메인 명이 쌍을 이루고, 관련 데이터 무결성 제약이 나와야 함


Integrity Constraints (무결성 제약)
- not null - 널 값을 허용하지 않음
- primary key (A1, ..., An) - 주 키를 선언, not null이 포함되어 있음
- foreign key (A1, ..., An) references R - 외래 키 선언


alter Table - 스키마 삭제 및 변경 (in DDL)
Alter table r add A D;
- A is attribute name to be added to realtion r and D is the domain of A - A가 속성 이름, D는 도메인(인스턴스의 특성)
- The new attributes have null values - 아직 값이 없으므로 null 값이 배정됨
Alter table r drop A;
- A is the attribute name of relation r that will be dropped
- Dropping attributes not supported by many databases - 속성 제거 기능을 지원하지 않은 DBMS가 다수 있음
- Alter table student add constraint myConst
foreign key (deptName) references DEPARTMENT on delete cascade;
- - student.deptName이 DEPARTMENT 테이블의 기본 키 같은 값을 참조하도록 하고, 그 부서가 삭제되면 관련된 학생도 같이 삭제되게 만들겠다는 제약조건을 추가
DROP vs. DELETE
- DROP means delete the table and its contents - 스키마 자체(관계 튜플까지) 삭제하는 DDL 기능을 함
- DELETE means delete all contents of the table, but the table schema remains unchanged - 내용물 즉 튜플을 삭제하는 DML 문장
DML SQL
SQL provides four key words for DML: Select, Insert, Delete, Update
Insert - 데이터베이스 튜플을 입력하는 연산
ex)
Insert into course (cID, title, deptName, credit)
values ('437', 'Advanced Databases', 'CS', 4);ex2)
Insert into professor
select * from professor;- professor 튜플 개수가 2배가 되는 효과, 무한 루프가 발생하지 않음
Deleteion - 튜플을 삭제하는 연산
ex)
Delete from professor- delete all professor tuples
ex2)
Delete from professor where deptName='EE';- delete all EE professors from the professor table
ex3)
Delete from professor where salary < (select avg(salary) from professor);- delete all professors whose salary is less than the average salary of all professors
Updates - 튜플을 수정하는 연산
ex)
Update professor
set salary = salary*1.03
where salary > 7000;- update salary to 1.03 times whose salary is bigger than 7000
ex2)
Update professor set salary = case
when salary <= 7000 then salary * 1.05
else salary * 1.03
end;- case문
ex3)
Update student
set totalCredit = 0
where totalCredit is null;
Select statements - retrieve query
ex)
Select pId, name, deptName, salary/12
from professor;- salary는 12로 나눈 값들로 나옴

- select, from은 필수로 생략이 불가능
- 반드시 위의 순서를 지켜야 함
- having 절은 group by 절이 나오지 않으면 나올 수 없음
SQL allows duplicates in relations as well as in query results - SQL은 튜플의 중복을 허용함
- 'distinct' eliminate duplicates of tuples - select 절에 위치하는 속성 앞에 distinct 키워드를 넣으면 중복이 제거됨
ex)
Select distinct deptName
from professor;- 동일한 deptName 제거
- 'all' specifies that duplicates are not removed(default value) - 'all'은 중복 값을 허용하며 이는 default 값임
ex)
Select all deptName
from professor;- 중복 deptName 허용
WHERE Clause
- specifies conditions that the result must satisfy - 튜플이 만족하여야 하는 조건을 명시하며 관계대수의 선택조건에 대응
- logical connectives 'and', 'or', and 'not' can be used
ex)
Select name
from professor
where deptName = 'cs' and salary > 8000;
FROM Clause
- lists the relations involved in the query - 질의에 관련이 있는 테이블을 나열하여야 하며 관계대수의 카티시안곱 연산과 대응
ex)
Select *
from professor, teaches;- professor과 teaches의 카티시안곱 연산의 결과를 검색하는 질의
GROUP BY Clause
- groups the result based on one or more attributes - 속성을 기준으로 결과를 그룹으로 묶음
- aggregate function(집계함수)와 함께 자주 사용됨 (SUM, AVG, COUNT, MAX, MIN)
ex)
Select deptName, COUNT(*), AVG(salary)
from professor
group by deptName;- 학과별 교수의 수와 급여 평균치
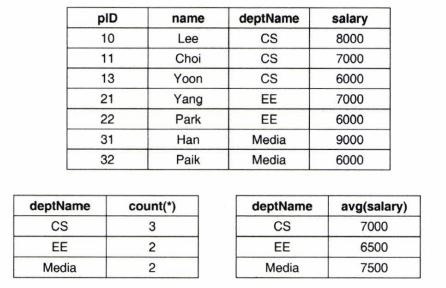
ex2) Erroneous query
Select deptName, pID, avg(salary)
from professor
group by deptName;- pID 속성은 group by절에 나오지 않았으므로 오류가 발생함 (pID값은 그룹 수보다 많이 존재하며 이 경우 보여주어야 하는 pID 값을 선정할 수 없기 때문)
ex3) Careful!
Select avg(salary)
from professor
group by deptName;- deptName이 출력이 안되므로 {7000, 6500, 7500} 값만 반환되어 어느 학부 평균인지 모르게 됨
HAVING Clause
- specifies conditions on groups, not individual rows - 그룹에 대해 조건을 걸 때 사용 (WHERE은 행에, HAVING은 그룹에)
- 관계대수에서 직접 대응은 없지만, 그룹 결과에 조건 필터링 역할
- group에 대한 where 절이라고 생각하면 쉬움
ex)
Select deptName, COUNT(*)
from professor
group by deptName
having COUNT(*) > 3;- 교수의 수가 3명 초과인 학과만 출력
ex2) 다섯 명 이상의 종업원을 가진 부서에 대하여 4만 불 초과의 소득을 가진 종업원의 수를 구하시오

Wrong query
Select dname, count(*)
from department, employee
where dnumber=dno and salary>40000
group by dname
having count(*)>5;- 소득이 40000이하인 종업원들을 모두 제외한 뒤 group by를 하게 되면 소득이 40000 초과인 종업원이 5명 이상인 부서를 구하는 꼴임
Correct query
Select dname, count(*)
from department, employee
where dnumber=dno and salary>40000 and
dno in (select dno
from employee
group by dno
having count(*)>5)
group by dname;- (dno가 종업원이 5명 이상인 부서에 속한 종업원의 dno에 포함되어 있을 때)를 where 조건에 추가한 뒤 group by를 해주면 됨
ORDER BY Clause
- sorts the result based on one or more attributes - 속성 값을 기준으로 정렬 (오름차순 ASC / 내림차순 DESC)
- 관계대수에 직접적인 연산은 없지만, 출력 순서를 조정
ex)
Select name, salary
from professor
order by salary DESC;- 교수 이름과 급여를 출력하되, 급여 높은 순으로 내림차순 정렬
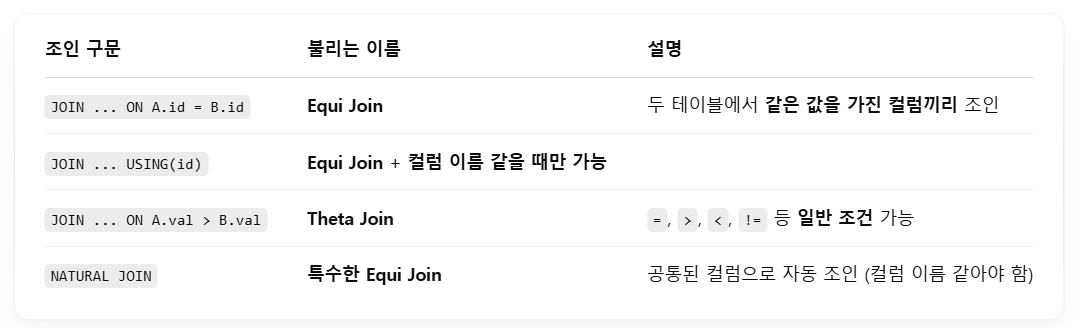
Joins
- 조인은 where 절에서 명시 가능
ex)
Select name, cId
from professor, teaches
where professor.pId = teaches.pID;- pID 값으로 조인
ex2)
Select title, name
from teaches as t, course as c, professor as p
where t.cID=c.cID and t.pID=p.pID and c.deptName='CS';- teaches, course, professor 간에 equi-join(동등조인)이 필요한 질의어로 deptName 속성은 모두 존재하므로 course나 professor 아무거나로 표현 가능
Natural Joins
- Natural join matches tuples with the same values for all common attributes - 두 테이블에서 동일한 이름을 가지는 속성 간에 조인 연산을 적용
- Retains only one copy of each common column - 중복이 제거되어 한 번만 나옴
ex)
Select *
from professor natural join teaches;- pID 속성 값이 같은 터플이 조인됨며 총 8개의 속성이 나옴
ex2)
Select *
from professor, teaches
where professor.pID=teaches.pID;- equi-조인 된 값이 나오며 professor.pID와 teaches.pID가 모두 나오므로 총 9개의 속성이 나옴
ex3) professor name과 강의하는 course title을 검색하는 질의어를 찾고자 할 때
Select name, title
from professor natural join teaches natural join course;- Incorrect one ('deptName'이 겹침) >> deptName도 조인 연산에 참여해 버림

Correct version 1.
Select name, title
from professor natural join teaches, course
where teaches.cID = course.cID;
Correct version 2.
Select name, title
from (professor natural join teaches) join course using(cID);
Correct version 3.
Select name, title
from teaches t, course c, professor p
where t.cID=c.CID and t.pID=p.pID;
Rename Operations
- SQL allows renaming relations and attributes using the 'as' clause
ex)
Select sID, name myName, deptName
from student;- name is renamed with myName
ex2)
Select pID, name, salary/12 as monthlySalary
from professor;- salary를 12로 나눈 값이 monthlySalary로 renamed 됨
ex3)
Select distinct T.name
from professor as T, professor as S
where T.salary > S.salary and S.deptName='CS';- professor 테이블을 두 번 renamed 하여 두 개 터플을 동시에 가져오는 효과를 볼 수 있음.
String Operations
- SQL includes a string-matching operator for comparisons(비교) on character strings
- The operator 'like' usese patterns that are described using two special characters
- percent(%): matches any substring(including an empty string) - 임의 길이 문자열을 의미
- underscore(_): matches any single character - 길이가 하나인 임의 스트링(한 문자)
- concatenation(||): 연결
ex)
Select name
from professor
where name like '%da_');- '(임의 길이 문자열)da(길이가 하나인 임의 스트링)'을 찾음
ex2)
Select cID
from course
where title like '100\%' escape '\';- % 기호를 임의 스트링이 아닌 퍼센트 기호로 인식하게 하기 위하여 escape '\'를 사용
'<>' means '!='
ex) 'σ score <> 100 (Student)' == 'σ score != 100 (Student)'
- 관계 대수에서는 '<>'나 '≠'만 가능
'between' comparison operator in WHERE Clause
ex)
Select name
from professor
where salary between 5000 and 6000;- salary>=5000 and salary<=6000과 동일
Tuple comparison in WHERE Clause
ex)
Select name, cID
from professor, teaches
where (professor.pID, deptName) = (teaches.pID, 'CS');- 일시적으로 professor, deptName 튜플을 만듦
- professor.pID = teaches.pID and professor.deptName='CS'와 동일
Duplicates
- SQL supports tuple duplicates in relations (i.e. muliset) - SQL 테이블은 동일 튜플의 중복을 허용하는 튜플의 멀티셋임
- 결국 SQL 문장의 의미는 멀티셋을 대상으로 하는 관계연산의 결과를 의미

Set operations
- union(합집합), intersect(교집합), except(차집합) - each of operations automatically eliminates duplicates(자동 중복 처리)
- To retain all duplicates(multiset relation) in the result, use 'union all', 'intersect all', 'except all'
- m+n times in 'r union all s' - 두 입력 멀티셋 테이블을 중복에 상관없이 add(더하는) 연산
- min(m, n) times in 'r intersect all s'
- max(0, m-n) time in 'r except all s'

Aggregate Functions (집계함수)
- avg: average value
- min: minimum value
- max: maximum value
- sum: sum of values
- count: number of values
ex)
Select count(*)
from student;- find the number of tuples of 'student' relation
ex2)
Select avg(salary), max(salary), min(salary)
from professor
where deptName='CS';- find the average salary, maximum salary, and minimum salary of professors in CS department
ex3)
Select count(distinct pID)
from teaches
where semester='Spring' and year=2010;- find the number of distinct(유일한 값) professors who teach a course in the Spring 2010 semester
- count(distinct gender)를 사용하면, 속성 값이 M or F만 있으므로 결과는 2이다.
Null Values and Aggregates (널 값과 집계 함수)
- All aggregate operations escept count(*) ignore tuples with null values on the aggregated attributes - count(*)을 제외한 집계함수들은 모두 null 값을 무시함
- 모든 값이 null 값이면 null을 반환
ex)
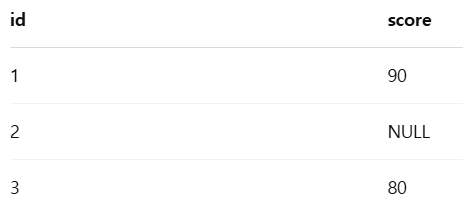
SELECT COUNT(score) FROM Scores;
-- 결과: 2 (NULL 제외)
SELECT COUNT(*) FROM Scores;
-- 결과: 3 (모든 행을 셈, NULL 무시 안 함)
SELECT AVG(score) FROM Scores;
-- 결과: (90 + 80) / 2 = 85 (NULL 제외)
ex2)
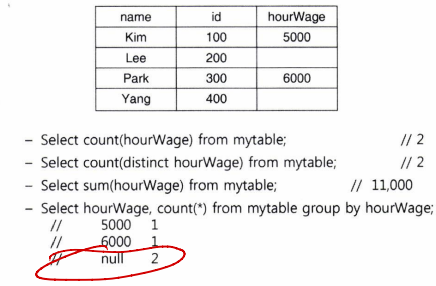
Joined Relations (조인 테이블)
- Join operations take two relations and return another as a result - join 연산은 두 개의 입력 테이블을 받아 한 개의 결과 테이블을 생성
- typically used as subquery expressions in the ''from' clause - from 절에서 조인 테이블을 생성한 후 이에 대한 추가적인 연산 가능
Inner join (내부 조인)
- join 연산을 의미하므로 생략 가능한 키워드임
ex)
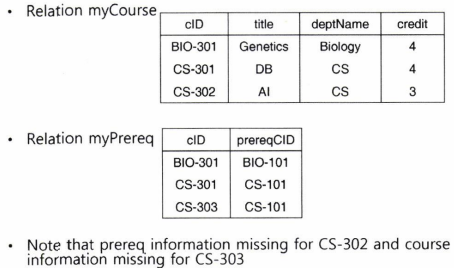
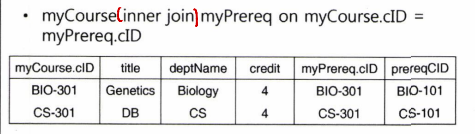
Outer join (외부 조인)
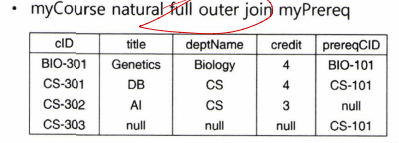
- An extension of the join operation that avoids loss of information - 조인 연산에서 값 매치가 되지 않아 손실되는 정보를 유지하려고 하는 연산임
- Computes the join and then adds tuples in the other relation to the result of the join (uses null values) - 일차적으로 조인 연산을 수행하고, 조인 연산에서 제외된 튜플을 널 값을 이용하여 결과 테이블에 첨가함
- Left outer join (왼쪽 외부 조인)
- Right outer join (오른쪽 외부 조인)
- Full outer join (양쪽 외부 조인)
ex)

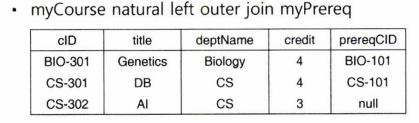
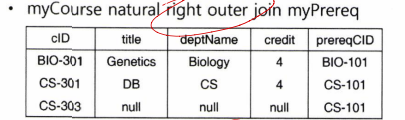
'Database' 카테고리의 다른 글
| [Database] 관계형 데이터 모델 (2장) (1) | 2025.04.10 |
|---|---|
| [Database] Database 소개 (1장) (1) | 2025.03.14 |

