
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
- 비트마스킹
- 최소 공통 조상
- ccw 알고리즘
- MongoDB
- Behavior Design Pattern
- 게임 서버 아키텍처
- 이분 탐색
- SCC
- 강한 연결 요소
- localstorage
- DP
- map
- 분리 집합
- Github
- trie
- Prisma
- Strongly Connected Component
- R 그래프
- Express.js
- PROJECT
- 트라이
- LCA
- 벨만-포드
- 그래프 탐색
- Binary Lifting
- 자바스크립트
- JavaScript
- Spin Lock
- 비트필드를 이용한 dp
- 2-SAT
- Today
- Total
dh_0e
[Database] SQLII 5.3~ 본문
Nested Subqueries(중첩 서브질의)
- select-from-where로 구성이 되는 서브질의를 다른 SQL 문장에 위치할 수 있음
- 테이블이 위치하는 장소에는 중첩 서브질의 표현이 이론적으로 가능하며 보통 where절 또는 from절에 위치함
- where절, from절에 존재하는 경우에는 보통 집합 포함 관계, 집합 비교, 집합 원소 개수 등의 조건을 사용함

IN 연산자
- 단일 값이 다수 값에 속하는지 검사
ex) Get names and salaries of professor who has ID with 10 or 21 or 22
SELECT name, slalry
from professor
where pID in (10, 21, 22); # == 'where pID=10 or pID=21 or pID=22;'
ex) Find course numbers offered in Fall 2009 but not in Spring 2019
(SELECT cID from teaches where semester='Fall' and year=2009)
escept
(SELECT cID from teaches where semester='Spring' and year=2010);
# ==
SELECT distinct cID
from teaches
where semester='Fall' and year=2009
and cID not in (SELECT cID from teachees
where semester='Spring' and year=2010);
Comparison Operators(비교 연산자)
- SQL offers operators (some, any, all, in) to compare single value with multiple values
ex
- (1 > 2): false
- (3 > all {2, 3}): false
- (3 > some {2, 3}): true
- (3 > any {2, 3}): true // any == some
- (5 = some {0, 5}): true
- (5 ≠ some {0, 5}): true
- some과 in은 "속한다"의 의미로 동일하지만 ≠some과 not in은 동일하지 않다.
- (5 < all {6, 7}): true
- (5 = all {4, 5}): false
- (5 ≠ all {6, 7}): true
- ≠al과 not in은 동일한 의미를 가지지만 all과 in은 동일하지 않다.
Correlated Subqueries
- 만약 내부 중첩 질의에서 외부 테이블을 참조하면 이를 상관 서브질의(Correlated Subqueries)라 부름
- 외부 테이블에서 가져오는 튜플이 매번 변하므로, 내부 중첩 질의 결과는 매번 다르고, 수행 시간이 많이 소요됨
ex) 서브질의에서 바깥 쿼리의 e1.dept_id를 사용하므로 상관 서브질의
SELECT name, salary, dept_id
FROM employee e1
WHERE salary > (
SELECT AVG(salary)
FROM employee e2
WHERE e1.dept_id = e2.dept_id
);
중첩 서브질의(Nested Subquery) VS 상관 서브질의(Correlated Subquery)
| 항목 | 중첩 서브질의 | 상관 서브질의 |
| 실행 횟수 | 한 번 | 바깥 쿼리 행마다 반복 |
| 바깥 쿼리 참조 | ❌ 없음 | ✅ 있음 |
| 성능 | 더 빠름 | 느림 |
| 사용 목적 | 전체 기준 비교 | 행마다 다른 조건 비교 |
"exists" Construct
- "exists r"은 r이 공집합이 아닐 때만 참이다.
- "not exists r"은 r이 공집합일 때만 참이다.
ex) Find all course numbers taught in both the Fall 2009 semester and in the Fall 2010 smester
SELECT S.cID
from teaches as S
where S.semester='Fall' and S.year=2009 and
exists (SELECT *
from teaches as T
where T.semester='Fall' and T.year=2010
and S.cID=T.cID);
"for all" Queries
- for all 의미를 구현하는 연산자는 SQL에서 제공되지 않음
- "모든 과목"을 구현하기 위해선 not exists를 사용
- 집합 X가 Y를 포함하면 X-Y=∅가 성립하며 이는 "not exists(X excepts Y)"로 구현
ex) Find all student IDs and names who have taken all courses offered in 'CS' department
SELECT S.sID, S.name
from student as S
where not exists(
(SELECT cID
from course
where dpetName='CS') # CS 수업들의 cID들 (X)
except
(SELECT T.cID
from takes as T
where S.sID=T.sID) ); # 선택된 학생 S가 듣는 수업들의 cID들 (Y)
# X-Y=선택된 학생 S가 듣지 않는 CS 수업들의 cID
# 가 비어있으면 CS 학과의 수업을 모두 듣는 학생임
"unique" Construct
- unique는 인자형식으로 표현되는 서브질의 결과에 중복성이 있는지 검사함
- unique(r)에서 r이 공집합이라면 unique(r)은 참이다.
- 튜플 중의 속성이 한 개라도 null 값을 가지면 동일하지 않다고 판별함
- unique {<1, 2>, <1, 2>}: false
- unique {<1, 2>, <1, 3>}: true
- unique {<1, 2>, <1, null>}: true
- unique {<1, null>, <1, null>}: true
- 근데 별로 쓸 일 없어서 대부분 DBMS에서 지원하지 않음
ex) Find all courses that were offered at most once in 2009
SELECT C.cID
from courses as C
where 1 >= (SELECT count(T.cID)
from teaches as T
where C.cID=T.cID and T.year=2009);
# "1 >= count(TARGET)" == "unique"
SELECT C.cID
from courses as C
where unique (SELECT T.cID
from teaches as T
where C.cID=T.cID and T.year=2009);
"from" 절의 Subqueries
- 서브질의를 from 절 안에서 사용할 수 있음
ex) Find department name and the average salary of the professors of the dpartment where the average salary is greater than 6900
SELECT deptName, avg(salary) as avgSalary
from professor
group by deptName
having avg(salary) > 6900;
# ==
SELECT deptName, avgSalary
from (SELECT deptName, avg(salary) as avgSalary
from professor
group by deptName)
where avgSalary > 6900;
# ==
SELECT deptName, avgSalary
from (SELECT deptName, avg(salary)
from professor
group by deptName) as deptAvg(deptName, avgSalary)
where avgSalary > 6900;
ex) Find the maximum total salary of department across all departments
SELECT sum(salary)
from professor
group by deptName
having sum(salary) >= all(SELECT sum(salary)
from professor
group by deptName);
# ==
SELECT max(totalSalary)
from (SELECT deptName, sum(salary)
from professor
group by deptName) as deptTotal(deptName, totalSalry);
"lateral" Caluse
- 원래 from은 서브질의 참조가 안 됨
- lateral 절은 from 절에서 선행 관계 또는 서브질의를 참조하게 함
ex) To find professor names, their salaries, the average salary of their departments
SELECT P1.name, P1.salary, avgSalary
from professor P1, (SELECT avg(P2.salary) as avgSalary
from professor as P2
where P1.deptName=P2.deptName); # WRONG SYNTAX
SELECT P1.name, P1.salary, avgSalary
from professor P1, lateral (SELECT avg(P2.salary) as avgSalary
from professor as P2
where P1.deptName=P2.deptName); # RIGHT SYNTAX
"with" Clause
- with 절은 SQL 문장의 결과를 임시적으로 저장할 수 있어 복잡한 질의문을 효율적으로 작성할 수 있음
- 임시뷰(temporary view)를 만든다고 생각하면 됨
ex) Find the department with the maximum budget
SELECT deptName, budget
from department
where budget=(SELECT MAX(budget)
from department);
# ==
WITH maxBudget(value) as (SELECT max(budget) from department)
SELECT deptName, budget
from department, maxBudget
where department.buddget=maxBudget.value;
ex) Find all departments where the total salary is greater than the average of the total salary at all departments
with deptTotal(deptName, value) as
(select deptName, sum(salary)
from professor
group by deptName),
deptTotalAvg(value) as
(select avg(value)
from deptTotal)
select deptName
from deptTotal, deptTotalAvg
where deptTotal.value > deptTotalAvg.value;
Scalar Subquery
- SQL은 서브질의가 오직 한 개 속성을 반환하고 동시에 속성 값으로 한 개의 튜플(값)만을 반환하는 테이블이라면 서브질의가 연산 식에서 값이 반환되는 어떤 곳(Select, where, having)이라도 나탈 수 있게 하며 이러한 서브질의를 scalar 서브질의라 함
ex) Find department names along with the number of professors
SELECT deptName, (SELECT count(*)
from professor p1
where d1.deptName = p1.deptName)
from department d1; # 교수가 0인 dept도 모두 나옴
# !=
SELECT deptName, count(*)
from professor
group by deptName; # 교수가 0 인 dept가 나오지 않음
Ranking
- SQL server - top
- MySQL - limit
- Oracle - Rownum
- rank() 함수는 order by와 함께 쓰여서 순위를 나타냄
ex) Find the rank of each student
SELECT ID, rank() over (order by GPA desc) as sRank
from studentGrades;
SELECT ID, rank() over (order by GPA desc) as sRank
from studentGrades
order by sRank; # rank순으로 정렬
# =
SELECT ID, (1 + (SELECT count(*)
from studentGrades B
where B.GPA > A.GPA)) as sRank
from studentGrades A
order by sRank; # 결과는 같지만, correlated된 서브질의 형태로 실행이 비효율적임
rank() VS dense_rank()
- rank(): <10, 1> < 10, 1> <30, 3>, <30, 3>, <50, 5> ... 갭 차이 발생
- dense_rank(): <10, 1> < 10, 1> <30, 2>, <30, 2>, <50, 3> ... 갭 발생하지 않음
Ranks with Null
- null 값은 가장 처음에 위치하거나 가장 나중에 위치할 수 있음
- default 시에는 MAX 값으로 취급함
- ASC(오름차순)에선 마지막, DESC(내림차순)에선 처음에 등장
- "nulls first" or "nulls last"로 다음과 같이 설정 가능
SELECT ID,
rank() over (order by GPA desc nulls last) as sRrank
from studentGrades;
Ranking within Partition
- "partition by"로 각 파티션으로 나눠서 정렬하거나 랭킹을 매길 수 있음
ex) Find the rank of students within each department
SELECT ID, deptName,
rank() over (partition by deptName order by GPA desc) as deptRank
from studentGrades
order by deptName, deptRank; # deptName에서 오름차순 정렬, 동일 deptName에서는 deptRank 값의 오름차순으로 보임
Other Ranking Functions
| 함수 이름 | 의미 | 특징 요약 | 예시 값 (n=4) |
| RANK() | 동점 순위, 건너뜀 | 동점자 동일 순위, 다음 순위 건너뜀 (dense로 바꿀 수 있음) | 1, 2, 2, 4 |
| ROW_NUMBER() | 고유 번호 | 동점도 따로 번호 부여 (1부터 연속 증가) | 1, 2, 3, 4 |
| PERCENT_RANK() | 상대 순위 백분율 | (r-1)/(n-1), 0~1 사이 값, 동점자 동일 비율 | 0.00, 0.33, 0.67, 1.00 |
| CUME_DIST() | 누적 분포 비율 (비율 누적) | 작거나 같은 행 수 / 전체, 동점자 동일 비율 | 0.25, 0.5, 0.75, 1.0 |
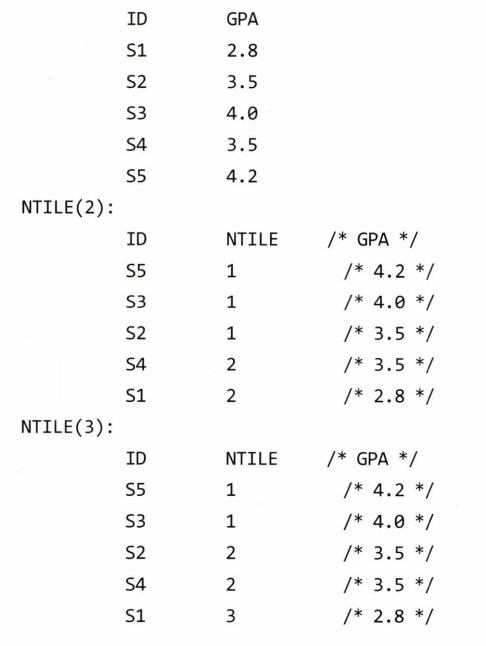
ntile() Ranking
- ntile() 랭크는 해당 속성 값을 기준으로 전체 테이블을 균등하게 n등분함
SLECT ID, ntile(N) over (order by GPA desc) as ntile # N == 몇 등분할 지
from studentGrades;
Reusing Existing Schema/data
CREATE table t1 like professor;
- To create a table with the same schema as an existing table
CREATE table t2 as (select * from professor) with data;
- To CREATE a table with the same schema and data
CREATE table t3 as (select * from professor where deptName='SW');
- SQL 표준에 의하면 with data 절이 없으면 복제하지 않지만, 이와 무관하게 많은 DBSM이 with data 절을 생략해도 데이터도 복제함
Large-Object Types
- 사진, 비디오 등과 같이 대용량 객체를 저장/관리하기 위해 blob, clob 데이터 타입을 지원함
- blob은 이진 데이터 형태의 큰 객체, clob은 문자 데이터 형태의 큰 객체
- SELECT로 불러올 수 없음
Built-in Date Types
date: dates, containing a (4 digit) year, month and date
- Example: date '2015-7-27'
time: time of day, in hours, minutes and seconds
- Example: time '09:00:30', time '09:00:30.75'
timestamp: date plus time of day
- Example: timestamp '2015-7-27 09:00:30.75'
interval: 시간 기간을 의미, interval 값을 가감하여 새로운 date, time, timestamp 값 생성 가능
- Example: interval '1' day
- Subtracting a date/time/timestamp value from another gives an interval value
- Interval values can be added to date/time/timestamp values
User-Defined Types
- "create type"을 이용하여 사용자가 원하는 데이터 타입 정의 가능
ex1)
Create type Dollars as numeric (12,2) final;
# final로 인해 Dollars로 다른 type을 못 만들게 설정 가능not final - 생성한 데이터 타입으로 다른 데이터 타입 생성 가능
ex2)
Create type myDepartment(deptName varchar(20), building varchar(15), budget Dollars);
# Dollars가 not final일 경우 가능
Domains
- "create domain"을 사용하여 사용자가 도메인(속성)을 정의할 수 있는 기능을 제공
ex1)
Create domain personName char(20) not null;- type과 사용법 및 개념이 유사하나, type과 달리 domain은 무결성제약을 가질 수 있음
ex2)
Create domain degreeLevel varchar(10)
constraint degreeLevelTest # 참조
check (value in ('Bachelor', 'Master', 'Doctorate'));
Transaction
- 트랜잭션은 ACID(atomicity, consistency, isolation, durability) 성질을 가지는 DB 연산의 나열(sequence) 임
- 암시적으로 DML 문장으로 시작하며, "commit work" or "rollback work"로 종료함
- commit은 성공적인 트랜잭션 종료, rollback은 비정상적인 트랜잭션 종료를 의미
- DDL은 자동으로 commit을 하며 스키마에 즉시 반영되므로 transaction과 관련 X
Indices(색인)
- index처럼 특정 column을 빠르게 검색하기 위한 자료 구조
- SQL 표준은 색인에 관련된 기능을 제공하지 않음
- DBMS는 자체적으로 색인 생성/관리/제거에 대한 기능 제공
ex) Create index myCourseIndex on course(cID);
- myCourseIndex: 색인의 이름
- course(cID): course 테이블의 cID 열에 대해 색인 생성
- → 나중에 WHERE cID = 341 같은 조건이 있을 때 빠르게 찾을 수 있음
'Database' 카테고리의 다른 글
| [Database] 오라클 실습 II (0) | 2025.05.20 |
|---|---|
| [Database] 데이터베이스 시스템 주요 기능 (0) | 2025.05.19 |
| [Database] SQL I, II (3, 5.1~5.2) (0) | 2025.04.13 |
| [Database] 관계형 데이터 모델 (2장) (1) | 2025.04.10 |
| [Database] Database 소개 (1장) (1) | 2025.03.14 |



