
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
Tags
- Github
- Strongly Connected Component
- 벨만-포드
- 최소 공통 조상
- 자바스크립트
- localstorage
- MongoDB
- LCA
- Behavior Design Pattern
- ccw 알고리즘
- Binary Lifting
- PROJECT
- R 그래프
- 게임 서버 아키텍처
- trie
- 분리 집합
- 이분 탐색
- 강한 연결 요소
- 그래프 탐색
- 비트마스킹
- Spin Lock
- 트라이
- DP
- 비트필드를 이용한 dp
- SCC
- Express.js
- 2-SAT
- Prisma
- map
- JavaScript
Archives
- Today
- Total
dh_0e
[OS] File System 본문
File Concept
- 파일(File): Byte들의 배열(Array of Bytes)로 정의되며, 관련 정보들의 집합(A Collection of Related Information)으로도 정의
- 추상화된 파일 객체를 다룸

File System
- File과 Physical Disk Block 간의 Mapping을 제공하며, Disk 위치 배치를 담당
- File Blocks >> Disk Blocks
- 독립성(Independence): 사용자는 File이 저장된 물리적 위치를 알 필요 없음
- Disk에 저장된 전체 File들을 총칭하며, File System 종류에 따라 File들의 배치나 구성이 달라질 수 있음

- 이 외에 Time(수정된 시각), Data(수정된 날짜), User Information, etc ..
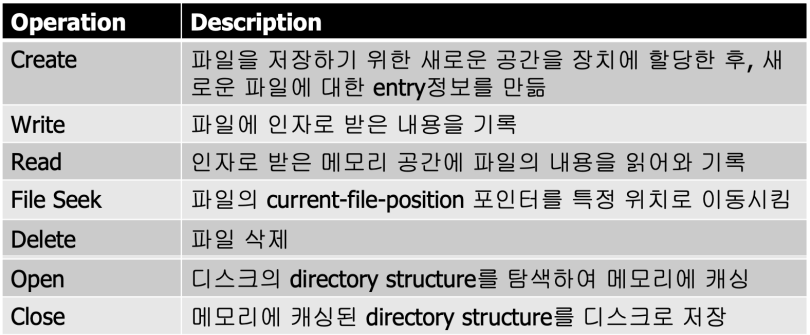
- Current-File-Position Pointer: File을 읽거나 쓸 때마다 자동으로 업데이트되며, Process가 File에 대해 어디까지 작업했는지를 기록하는 포인터 (PC와 비슷한 원리)
Open/Close Semantics
- 여러 Process가 File을 공유하는 경우
- 두 개의 Open File Table 유지
- 각 Process Table: 각 Process마다 유지하는 state를 가짐
- ex) File Pointer
- 각 Process Table: 각 Process마다 유지하는 state를 가짐
- Open은 Open Count를 하나 증가시키고, Close는 감소
- Delete 동작은 System-wide Table에서 Open Count를 확인한 후 이루어짐
- System-wide Table: 프로세스 독립적인 정보
- ex) Access date, File location, Open count
- System-wide Table: 프로세스 독립적인 정보
File Access Method
순차 접근(Sequential Access)
- File에 있는 정보에 대한 접근이 Record의 순서대로 이루어짐
- Operation
- Read next
- Write next
- reset
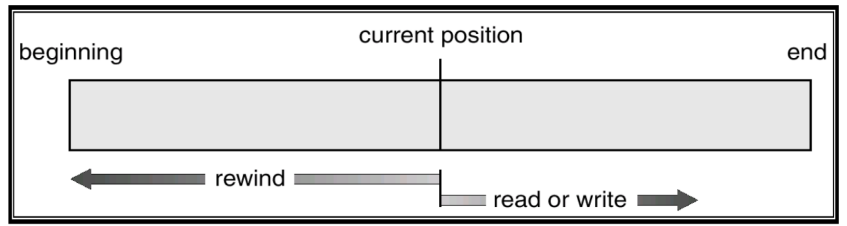
임의 접근
- File의 어떠한 위치라도 바로 접근하여 Read나 Write를 수행
- Operation
- Read n
- Write n
- reset
- 인자로 받는 n은 읽고자 하는 File의 Block Number

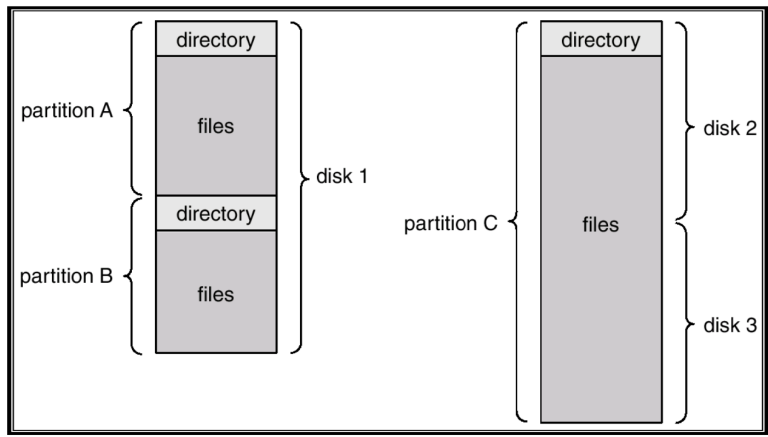
- 목적별로 파티션을 나눠서 사용
- 여러 개의 disk가 하나의 파티션이 될 수 있음
- disk 하나만 죽어도 시스템이 죽어버림
File System의 계층화
- File System은 일반적으로 여러 개의 계층으로 나뉘어져 구성
- 이유
- File System을 구현하고자 하는 장치가 다양할 수 있음
- 한 System에 1개 이상의 File System을 사용 가능하게 함
- 계층화된 구성을 통해서 File System에 유연성을 제공
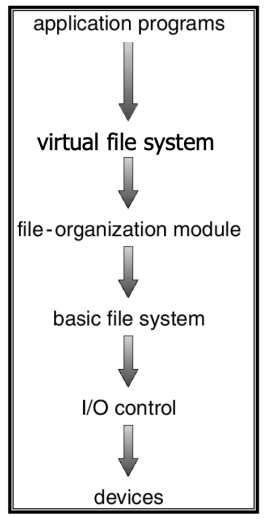
- 다양한 File system을 VFS를 통해 접근/관리 할 수 있음
- Diskmgmt.msc in Windows
- Fdisk in Linux

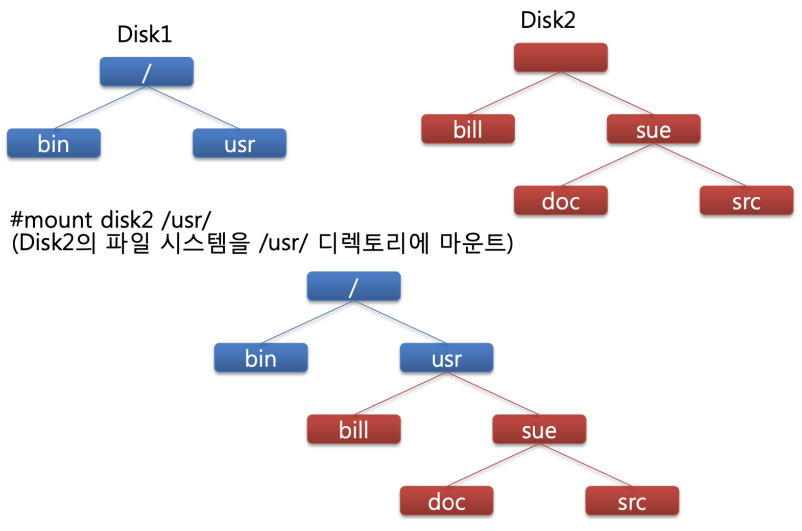
Mount
- Directory와 Device를 분리
- Window에선 거의 안 씀
- 비어 있는 Directory에 임의의 Device를 붙일 수 있음
- File을 사용하기 위해 Open을 하듯, Fiile System을 사용하려면 Mount가 필요로 함
- /home 위에 disk A /a/b/c Directory를 Mount하면 /home/a/b/c가 됨
Directory Structure Concept
- 모든 File들에 대한 정보를 가지는 Node들의 집합
- Directory Structure와 File은 모두 Disk 상에 있음

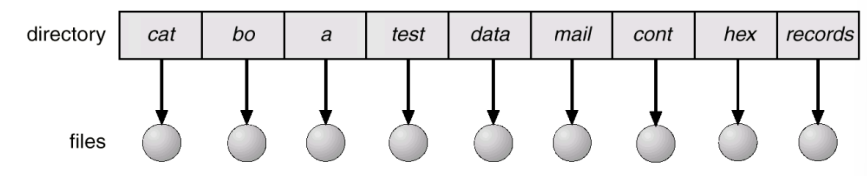
- Single-level Directory: 모든 사용자에 대해서 하나의 단일한 Directory
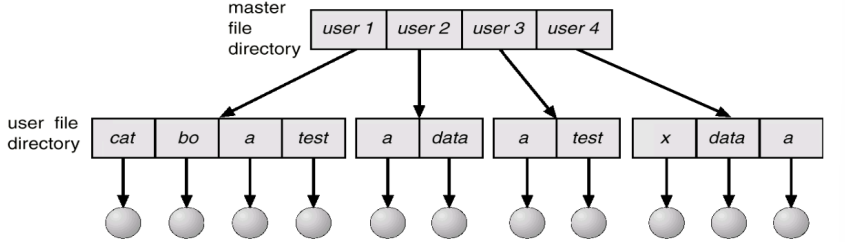
- Two-level Directory: 사용자마다 Directory를 분리
- Tree-Structured Directories
- 루트(root)를 가지는 트리 구조로 디렉토리를 구성
- 효율적인 탐색, Grouping 특성
- Window가 사용중인 구조
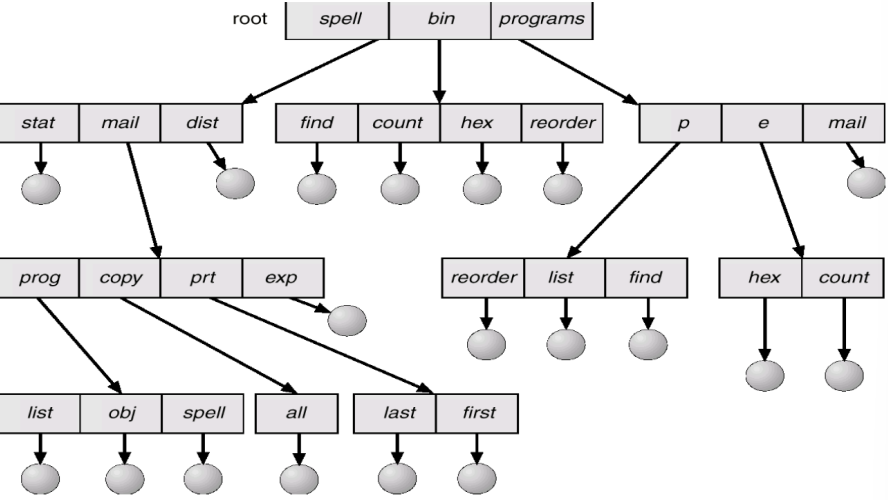
- Acyclic-Graph Directories
- 둘 이상의 서로 다른 이름을 이용(Aliasing)하여, File이나 Sub Directory를 공유
- Dangling Pointer가 생길 수 있음
- ex) 예시 그림 가장 밑 Directoy인 list를 삭제할 경우

- General Graph Directory
- Cycle이 없도록 보장하는 방법
- Link를 File로만 가능하도록 함 (디렉토리 바로가기는 없음)
- 링크(Sharing): 이미 존재하고 있는 파일이나 디렉터리를 다른 디렉터리에서도 있는 것처럼 가리키는 기술
- ex) Window 바탕화면의 바로가기 아이콘
- 새로운 Link를 만들 때마다 Cyclee Detection Algorihthm을 사용하여 Cycle이 생기지 않는지 확인
- Link를 File로만 가능하도록 함 (디렉토리 바로가기는 없음)
- Cycle이 없도록 보장하는 방법

File 구현
- Disk Block: File System의 입출력 단위
- 고려 사항: 파일 구현에서는 파일 내용을 담고 있는 Data Block의 위치 정보를 어떻게 디스크에 저장할지가 중요
- Data Block 관리 4가지 방식
- 운영체제마다 파일을 구성하는 Data Block 정보를 관리하는 방식이 다르며, 주로 다음 네가지가 사용됨
- Contiguous Allocation (연속 할당)
- Linked List Allocation (연결 목록 할당)
- Linked List Allocation using an Index (색인을 이용한 연결 목록 할당)
- I-nodes (색인 노드)
- 운영체제마다 파일을 구성하는 Data Block 정보를 관리하는 방식이 다르며, 주로 다음 네가지가 사용됨
Contiguous Allocation(연속 할당)
- File을 물리적으로 연속된 Disk Block에 저장
- Frame Allocation에서의 Contiguous Allocation과 유사
- 장점
- 구현이 간단함
- 물리적으로 연속된 공간에 있으므로, 전체 File을 한 번에 읽어들일 경우 성능이 매우 뛰어남
- 단점
- File은 반드시 한번에 끝까지 기록 되어야 함
- 운영체제에서 File의 끝에 예비용 Block을 남겨둘 경우, Disk의 공간을 낭비하게 됨
- 예비용 Block: 파일이 커질 것을 대비해 미리 비어두는 공간
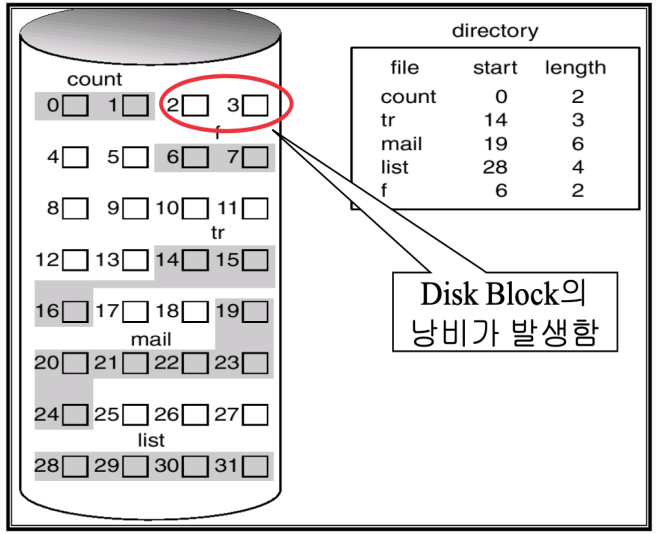
- 실제로 사용하기 어려움
- 이유: 얼마나 커질지 모름, 낭비가 너무 심함(Internal Fragment), 이동시 시간 지연
Linked List Allocation
- Disk의 Block을 Linked List로 구현하여, File의 Data를 저장하도록 함
- 장점
- File의 Data Block은 Disk의 어디든지 위치할 수 있음
- Linked List의 next pointer로 다음 공간을 알 수 있음
- 공간의 낭비가 없음 (Contiguous Allocation의 단점 해소)
- File의 Data Block은 Disk의 어디든지 위치할 수 있음
- 단점
- Random Access 불가능: 특정 위치를 찾기 힘듬
- File의 특정 위치를 찾기 위해서 해당 File의 시작 Node부터 찾아가야 함
- 다음 Data Block에 대한 Pointer로 인해, Data Block에서 Data를 저장하는 공간이 반드시 2의 배수가 아닐 수도 있음
- 대부분의 Program은 Read/Write하는 Data의 크기가 2의 배수이기 때문에 2의 배수가 아니면 binary로 탐색을 못해서 성능면에서 떨어질 수 있음
- ex) 물리적 블록 크기가 512 Byte에서 4 Byte가 포인터이기 때문에 대부분의 OS에서 512 Byte를 읽어오려고 시도할 때 508 Byte를 읽고, 블록 하나를 더 읽어야
- Random Access 불가능: 특정 위치를 찾기 힘듬

Linked List Allocation using an Index
- File의 Data에 관련된 Block을 하나의 Block에 모아 둠
- File의 Data Block 중 하나를 Index Block이라 하여, 모든 Data Block의 위치를 Index Block에서 알 수 있음
- Linked List Allocation 보다 개선된 점
- Random Access 시, 하나의 Data Block(Index Block)에서 찾아가고자 하는 Data Block의 위치를 알 수 있으므로, Linked List Allocation보다 빠르게 Random Access 가능
- 단점
- 최대 File의 크기가 고정됨
- Index Block의 크기가 고정되어 있기 때문에, Index Block에서 수용할 수 있는 Disk Block에 대한 Pointer의 수가 한정되어 있기 때문
- 최대 File의 크기가 고정됨
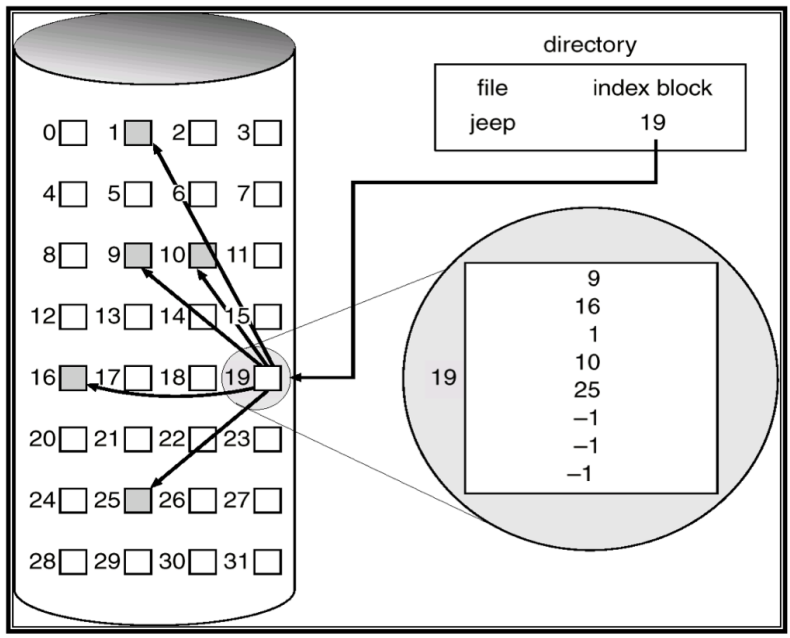
I-nodes
- 현재 사용하는 방식
- File에 대한 Data Block Index들을 Table 형태로 관리하는 방법
- 큰 Memory 영역을 관리할 경우에 1-level Paging보다 Multi-level Paging이 유리한 것과 유사함
- 구성 요소
- File에 대한 속성을 나타내는 Field
- 작은 크기의 File을 위한 Direct Index
- File의 크기가 커짐에 따라서 요구되는 Data Block의 Index들을 저장하기 위한 Index Table들
- Single Indirect Block: 하나의 블록이 Data Block의 주소를 가리킴 (Direct Index로 꽉 차 있는 테이블을 가리킴)
- Double Indirect Block: 하나의 블록이 Single Indirect Block의 주소를 가리킴
- Triple Indirect Block: 하나의 블록이 Double Indirect Block의 주소를 가리킴

Directory 구현
- Directory Entry: Directory를 표현하기 위한 자료구조
- File System의 File 구현에 따라 Directory Entry를 구성하는 Field도 달라짐
- 일반적인 Directory Entry: File의 이름, 속성과 같은 정보가 저장
- I-node를 사용하는 File System(UNIX): File Name과 I-node Number만이 저장됨
- 2가지 구현 방법
- Directories in MS-DOS
- Directories in UNIX
Directories in MS-DOS
- 파일 구현 방식: Linked List Allocation 방식

- Directory Entry의 First Block Number를 통해서 실제 File의 Data Block이 시작되는 Block을 알 수 있음
Directories in UNIX
- 파일 구현 방식: I-node 방식
- Directory Entry 구조: File 이름(14bytes)과 I-node Number(2bytes)로 이루어짐
- MS-DOS와 달리 File의 Attirbute, Ownership과 같은 정보는 해당 File의 I-node 자료 구조에 있기 때문
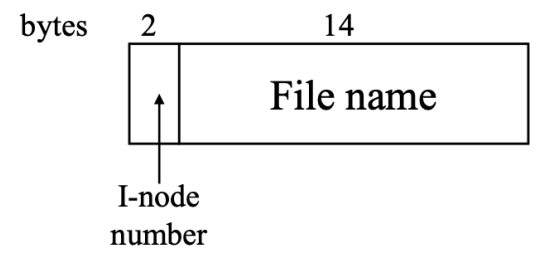
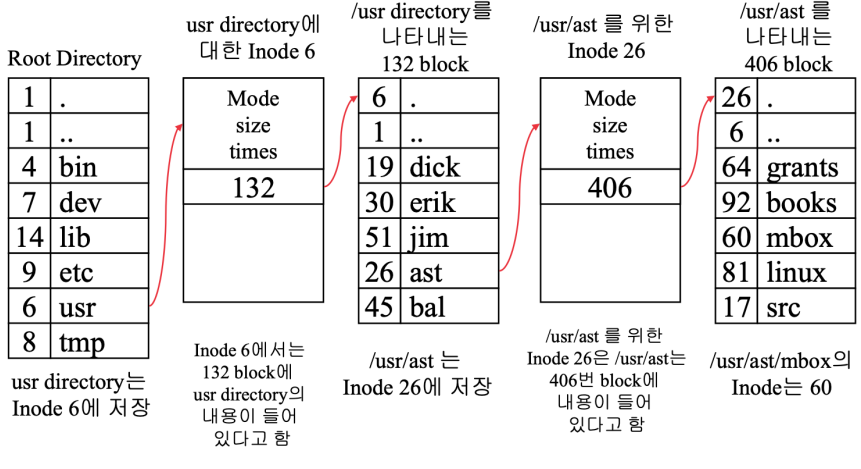
- 동작 예시: /usr/ast/mbox 파일의 경우, Root Directory에서 /usr/의 Inode 6을 찾고, Inode 6(132 block)에서 ast의 Inode 26을 찾고, Inode 26(406 block)에서 mbox의 Inode 60을 찾아 최종적으로 파일에 접근
Protection
- 저장된 정보에 부적절한 접근을 막는 것
- Types of Access
- Read, Write, Execute, Append, Delete, List(File의 속성이나 이름의 내용)
- 접근 모드: Read, Write, Execute
- 세 가지 분류의 사용자

- 관리자에게 고유의 이름을 가지는 Group G를 만들도록 요청, 그 그룹에 사용자들 추가
- 특정한 File 또는 하위 Directory에 대해 적절한 접근을 정의
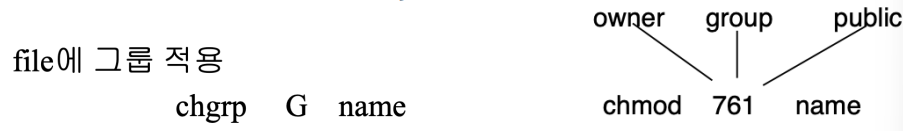
- 파일에 그룹 적용: chgrp G name (파일 name의 그룹을 G로 변경)
- 접근 권한 설정: ex) chmod 761 name
- 소유자(owner): 7(RWX)
- 그룹(group): 6(RW-)
- 기타 사용자(public): 1(--X)
- ex) chmod 755 file.c라고 칠 때:
- 7 (나) = 4+2+1 → rwx (다 할 수 있음)
- 5 (그룹) = 4+0+1 → r-x (읽고 실행만 됨)
- 5 (남들) = 4+0+1 → r-x (읽고 실행만 됨)
'Operating System' 카테고리의 다른 글
| [OS] Memory Management II (0) | 2025.12.07 |
|---|---|
| [OS] Memory mangement I (0) | 2025.12.06 |
| [OS] Synchronization II (0) | 2025.12.05 |
| [OS] Synchronization I (0) | 2025.12.04 |
| [OS] Thread (0) | 2025.11.28 |
'Operating System' Related Articles
more



