
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 |
Tags
- trie
- select 모델
- Binary Lifting
- 강한 연결 요소
- 벨만-포드
- Strongly Connected Component
- Overlapped Model
- reference counting
- Delete
- map
- 게임 서버 아키텍처
- DP
- Spin Lock
- PROJECT
- 비트마스킹
- 자바스크립트
- 비트필드를 이용한 dp
- Lock-free Stack
- SCC
- JavaScript
- 그래프 탐색
- Behavior Design Pattern
- 트라이
- Github
- 최소 공통 조상
- ccw 알고리즘
- 이분 탐색
- HTTP
- 2-SAT
- Prisma
Archives
- Today
- Total
dh_0e
[R Lang] 그래프 함수 I 본문
시각화(Visualization) 개요
| 항목 | 자료 (Data) | 정보 (Information) |
| 정의 | 정리되지 않은 Raw Data, 관찰이나 측정을 통해 인지된 단순한 사실이나 값들의 집합. | 자료를 의미있는 형태로 체계화/조직화한 데이터. 판단 및 의사결정의 근거가 됨. |
| 특징 | 단순 사실 | 해석 및 정리된 결과, 통찰력 제공 (시각화로 표현) |
데이터 특성
- 범주형 자료(Categorical data) = 질적 자료(Qualitative data)
- 특징: 성별, 혈액형, 찬반 등 숫자로 표시할 수 없거나, 숫자로 바꾸더라도 대소 구분이 불가능한 자료로 산술 연산이 적용되지 않음
- 연속형 자료(Numerical data) = 양적 자료(Quantitative data)
- 특징: 크기가 있는 숫자로 구성되며, 대소 비교 및 평균, 최솟값, 최댓값 등 산술 연산이 가능한 자료
- R에서의 저장:
- 단일 변수 자료: 벡터(Vector)
- 다중 변수 자료: 매트릭스(matrix)나 데이터 프레임(data frame)
- R에서 열의 개수는 변수의 개수가 됨
데이터 시각화 개요 및 유형
- 데이터 시각화(Data Visualization): 숫자 형태의 데이터를 그래프나 그림 형태로 표현하여, 데이터 분석 결과를 직관적으로 이해하고 핵심을 명확하게 전달하는 과정
- 목적: 방대한 데이터 속에 숨겨진 패턴이나 규칙을 발견하고, 신속한 현상 파악 및 미래 예측에 기여
- 발견 용이성: 평균적인 경향, 이상값(Outlier) 발견이 쉬움
- 시각화의 3가지 주요 유형
- 정보 시각화(Information Visualization): 대규모 데이터를 통계표, 그래프, 이미지 등으로 요약적으로 표현하여 추상적 데이터를 사람이 쉽게 인지하도록 함
- 과학적 시각화(Scientific Visualization): 과학적 현상을 그래픽으로 설명하여 과학자들이 데이터를 이해하고 통찰력을 얻도록 돕는 목적 (컴퓨터 그래픽의 하위 집합)
- 인포그래픽(Infographic): 정보(Information)와 그래픽(Graphic)의 합성어로, 다량의 정보를 차트, 지도, 다이어그램 등을 활용하여 빠르고 효과적으로 전달하며 정보 기억력을 상승시킴
시각화 기술 분류 (정보 시각화 중심)
| 유형 | 설명 | 주요 기법 |
| 시간 시각화 (Time) | 시간에 따라 변화하는 데이터를 표현. | 분절형 (막대, 누적막대), 연속형 (시계열, 계단식 그래프) |
| 분포 시각화 (Distribution) | 데이터를 부분으로 분리하고 부분 간의 관계 표현. | 파이 차트, 도넛 차트, 누적 영역 그래프, 트리맵 |
| 관계 시각화 (Relationship) | 변수들 간의 연관성/영향력 파악. | 산포도(Scatter Plot), 버블 차트 |
| 비교 시각화 (Comparison) | 여러 변수의 데이터값들을 비교. | 박스플롯(Boxplot), 히트맵, 체르노프 페이스 |
| 공간 시각화 (Space) | 데이터를 위치 정보(좌표)에 따라 지도 등에 표현. | 점/선/버블 차트가 포함된 지도, 스몰 멀티플 |








R 그래프 함수의 구분
- 고수준 그래프 함수(High-level Graphic)
- 역할: 하나의 완성된 그래프(점, 선, 막대, 히스토그램, 파이차트 등)를 그리는 핵심 함수
- 기본적으로 그림 창에 하나만 출력됨
- ex) plot(), barplot(), boxplot(), hist(), pie()
- 저수준 그래프 함수(Low-level Graphic)
- 역할: 그래프를 장식(Decoration)하고 설명을 돕는 보조적인 함수 (점, 선, 좌표축, 문자 등을 추가)
- ex) axis(), legend(), lines(), point(), text(), title(), par()
- R은 기본 패키지 함수 외에도 고급 그래프를 제공하는 ggplot2 패키지를 많이 사용함 (그래프 함수 II에서 다룸)
plot() 함수
- 일반적인 그래프 시각화 함수로 직선, 점 등 여러가지 형태의 플롯이 가능
- 그래픽 관련해서 가장 많이 사용되는 고수준 그래프 함수로 분포도나 꺾은선 그래프 등을 그릴 수 있음
- 호출 형식: plot(x, y, main=, sub=, xlab=, ylab=, type=, axes="", col="", pch=)
x <- c(29,14,9,26,15,13,28,24,17,4,19,22,2,25,8,6,16,18,21,30)
y <- c(9,3,26,27,10,21,8,4,28,24,5,6,22,29,20,25,12,1,2,15)
plot(x,y,main="plot의 전체 제목", sub="plot의 부 제목", xlab="x축의 제목", ylab="y축의 제목")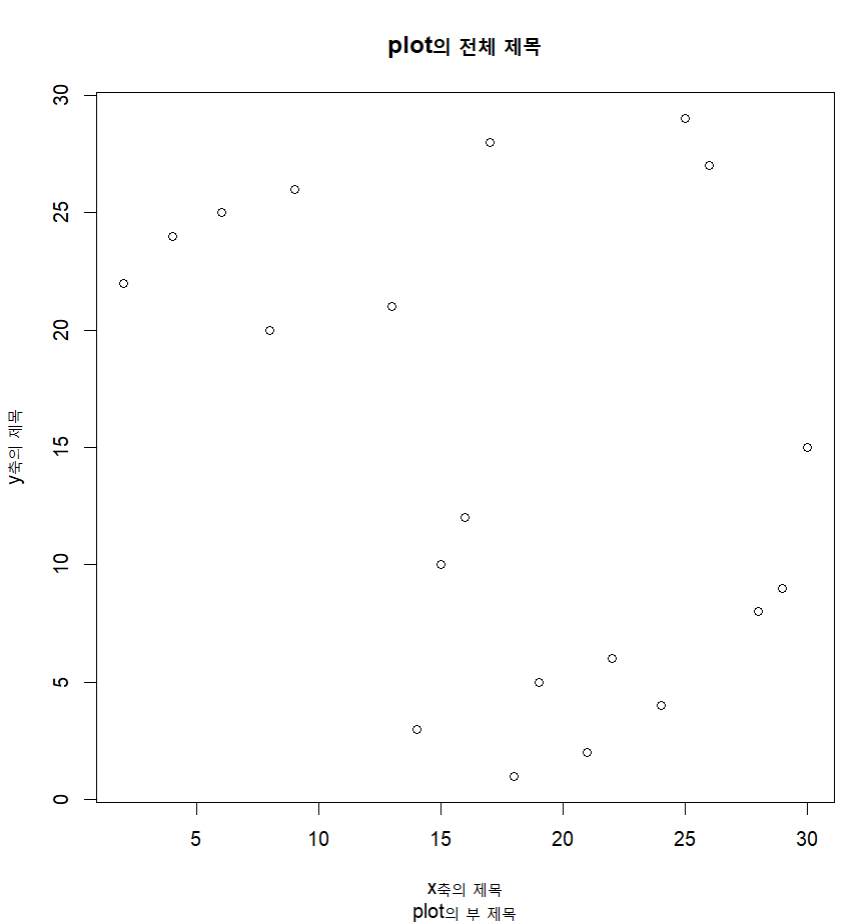
head(cars)
# speed dist
# 1 4 2
# 2 4 10
# 3 7 4
# 4 7 22
# 5 8 16
# 6 9 10
plot(cars, type="p", main="cars")
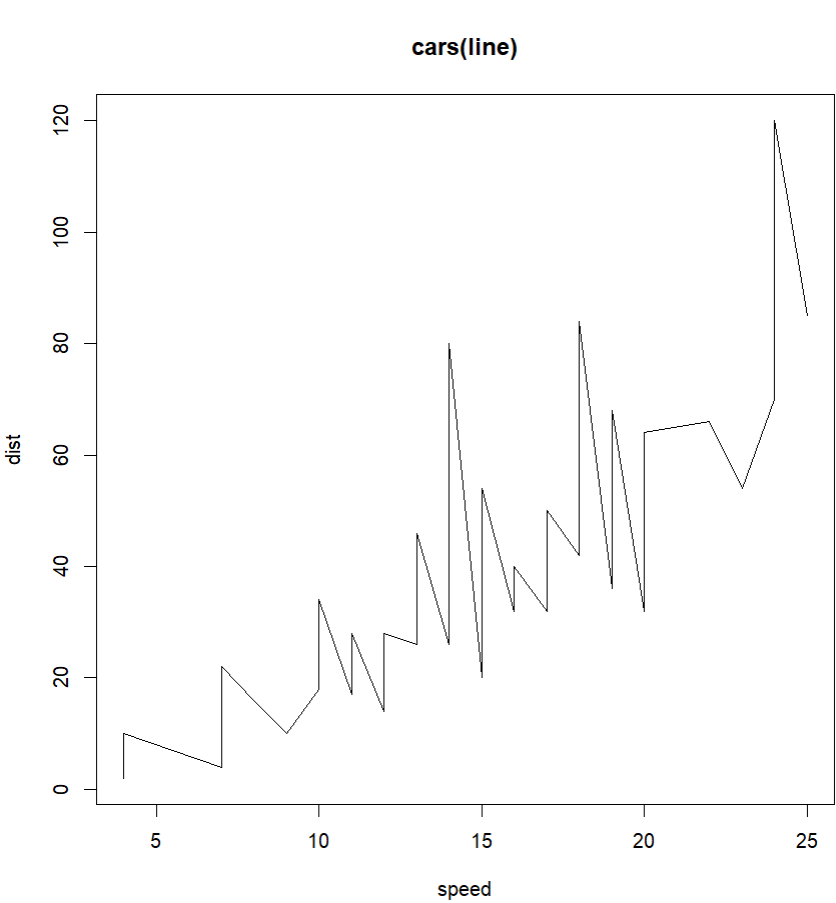
plot() 함수의 type 종류
- p: 점
- l: 선
- b: 점과 선
- o: 선이 점을 통과
- h: 수직선으로 된 히스토그램
- s: 계단형 그래프
- S: 다른 계단형 그래프
- n: 그래프 없음
- type 옵션에서 점 모양을 표시하는 경우 pch의 번호와 종류는 다양한 도형을 표시
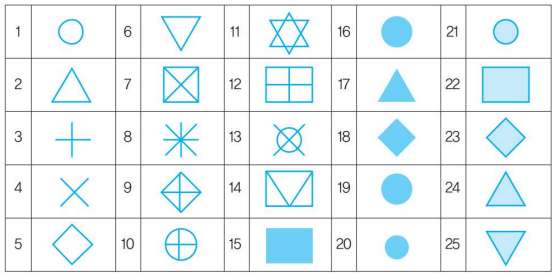
ex)
plot(cars, type="p", main="cars", pch=13)
par() 함수
- 한 화면에 중복 그래프를 그리거나, 한 화면을 여러 영역으로 분할하여 다수의 그래프를 한 화면에 그릴 수 있는 환경을 제공
- 그래프 출력 형식을 변경해주는 저수준 그래프 함수
- (1) 한 화면에 중복 그래프 그리기
- 고수준 그래프 함수를 이용한 그래프를 그릴 경우 par(new=T)를 사용하여 중복 그래프 작성
data <- c(5, 7, 3, 4, 5, 9, 10)
barplot(data) # 막대 그래프 작성
par(new=T) # 겹쳐서 출력 허용
plot(data, type="o") # 선 그래프 작성
- (2) 화면 분할 그래프 그리기
- mfrow=c(nrows, ncols)나 mfcol=c(rnows, ncols) 옵션을 사용하여 한 화면을 nrows*ncols개의 여러 영역으로 분할
- mfrow: 행 단위로 채움
- mfcol: 열 단위로 채움
- mfrow=c(nrows, ncols)나 mfcol=c(rnows, ncols) 옵션을 사용하여 한 화면을 nrows*ncols개의 여러 영역으로 분할
par(mfrow=c(3,3)) # 3x3으로 화면 분할, row(행) 단위로 채움
plot(x, y, main="Plot p-type", xlab="x-label", ylab="y-label", type="p")
plot(x, y, main="Plot l-type", xlab="x-label", ylab="y-label", type="l")
plot(x, y, main="Plot b-type", xlab="x-label", ylab="y-label", type="b")
plot(x, y, main="Plot c-type", xlab="x-label", ylab="y-label", type="c")
plot(x, y, main="Plot o-type", xlab="x-label", ylab="y-label", type="o")
plot(x, y, main="Plot h-type", xlab="x-label", ylab="y-label", type="h")
plot(x, y, main="Plot s-type", xlab="x-label", ylab="y-label", type="s")
plot(x, y, main="Plot S-type", xlab="x-label", ylab="y-label", type="S")
plot(x, y, main="Plot n-type", xlab="x-label", ylab="y-label", type="n")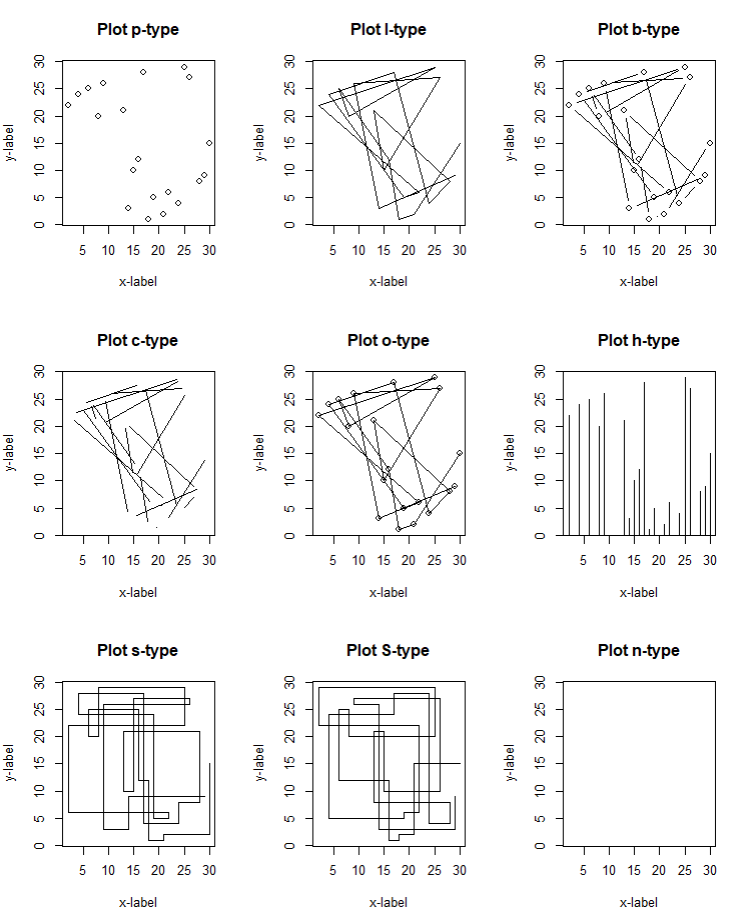

barplot() 함수
- 막대 그래프를 작성하는 고수준 그래프 함수
- (1) 단순 막대 그래프
- 'horiz=T'를 사용하여 가로형 막대 그래프를 표현
par(mfrow=c(2,1)) # 2x1 화면 분할
data <- c(5, 7, 3, 4, 5, 9, 10)
barplot(data) # 세로형 막대 그래프
barplot(data, horiz=TRUE) # 가로형 막대 그래프
- (2) 다중 막대 그래프
- 'beside=T'로 그룹 안의 값들을 옆으로 나란히 그리는 막대 그래프 표현 (기본값은 FALSE: 쌓아서 그리는 누적 막대 그래프)
par(mfrow=c(3, 1))
data <- matrix(c(5, 9, 10, 3, 5, 7, 3, 4), nrow=4, ncol=2) # 행렬 자료구조
barplot(data)
barplot(data, beside=T)
barplot(data, beside=T, main="학생수", legend=c("1학년", "2학년","2학년","3학년"))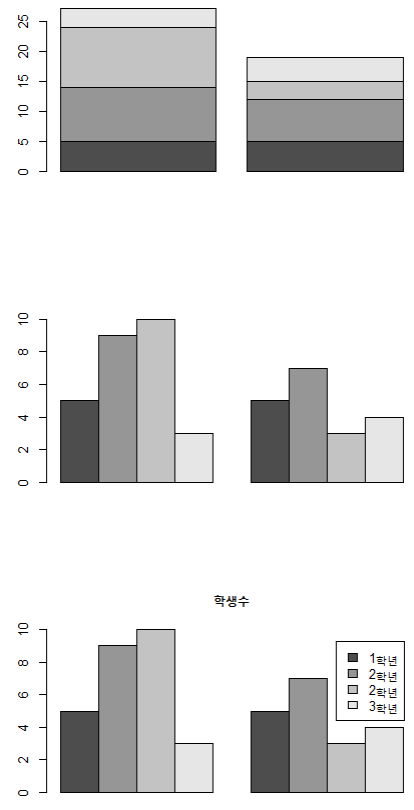
- "legend=" 인수를 사용하여 범례를 표시할 수 있음
lines() 함수
- 이미 떠 있는 그래프에 선 그래프를 추가(이중 선 그래프)로 작성하는 저수준 그래프 함수
- plot() 함수로 그래프를 그려놓은 후 type을 "l", "o"을 사용하여 선 그래프를 추가
par(mfrow=c(1,1))
# 그래프 데이터 생성
x <- c(182, 190, 213, 205, 231, 250, 242)
# 선그래프 작성
plot(x, type = "o",col = "red", xlab = "년도", ylab = "억원", main = "매출현황")
y <- c(190, 180, 200, 210, 220, 234, 235) # 이중 선그래프 데이터 생성
lines(y, type = "b", col = "blue") # 선(+점) 추가, 다중 선그래프
- lty(line type)
- "solid"(기본값) or 1: 실선
- "dashed or 2: 대시선
- "dotted" or 3: 점선
- "dotdash" or 4: 점-대시 혼합선
- "longdash" or 5: 긴 대시선
# 기존 그래프 만들기
x <- seq(0, 2 * pi, length = 100)
y <- sin(x)
plot(x, y, type = "l", col = "blue", lwd = 2, lty = "dotted") # 점선
# 새로운 선 추가
new_x <- seq(0, 2 * pi, length = 100)
new_y <- cos(new_x)
lines(new_x, new_y, col = "red", lwd = 2, lty = "dashed") # 대시선 추가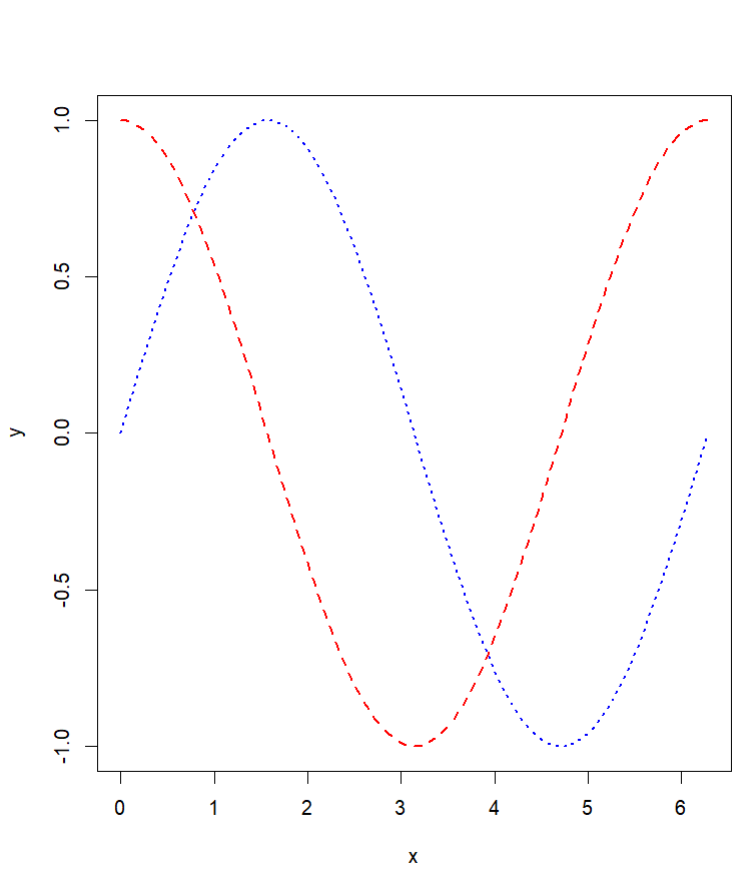
matplot() 함수
- 한 번에 여러 선이나 점(다중 선 그래프)을 그려주는 고수준 그래프 함수
# 다중 그래프 데이터 생성
x <- c(182, 190, 213, 205, 231, 250, 242)
y <- c(190, 180, 200, 210, 220, 234, 235)
z <- c(195, 185, 190, 215, 220, 230, 225)
data <- cbind(x, y, z ) # 행렬 구성
matplot(data, type = "b", col=2:4, pch=1) # 다중 선그래프 작성
lnd <- c("2022년 매출", "2023년 매출", "2024년 매출") # 범례
legend("topleft", legend =lnd , col=2:4, pch=1)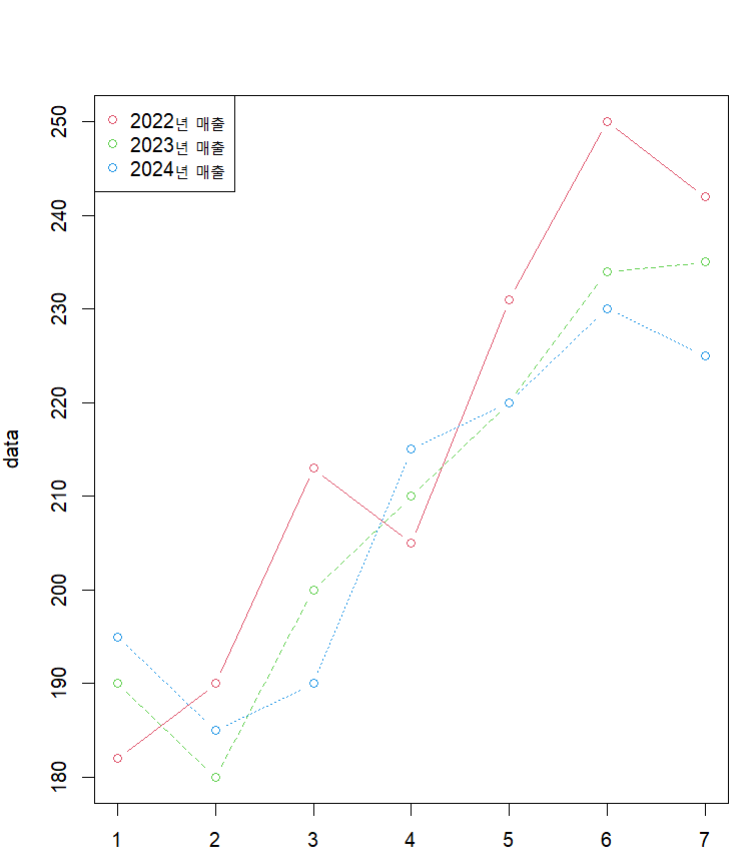
abline() 함수
- 이미 떠 있는 그래프 위에 직선을 추가할 때 쓰는 저수준 그래프 함수
- $y=ax+b$ 형태의 직선이나 $y=h$ 형태의 가로로 그은 직선 또는 $x=v$ 형태의 세로로 그은 직선 그래프를 만듬
- lty(선 스타일): 1(실선), 2(점선), 3(더점선)
- lwd(선 굵기): 실수로 입력
- col(색상): 1, 2, 3, 4 or black, red, blue, green
ex)
plot(cars, xlim=c(0, 25))
abline(a=-5, b=3.5, col="red") # y절편=-5, 기울기=3.5인 직선
abline(h=0, col="blue") # y=0 인 수평선을 그림
abline(v=0, col="green") # x=0 인 수직선을 그림
abline( a=0, b=1, col="purple") # y절편=0, 기울기=1인 직선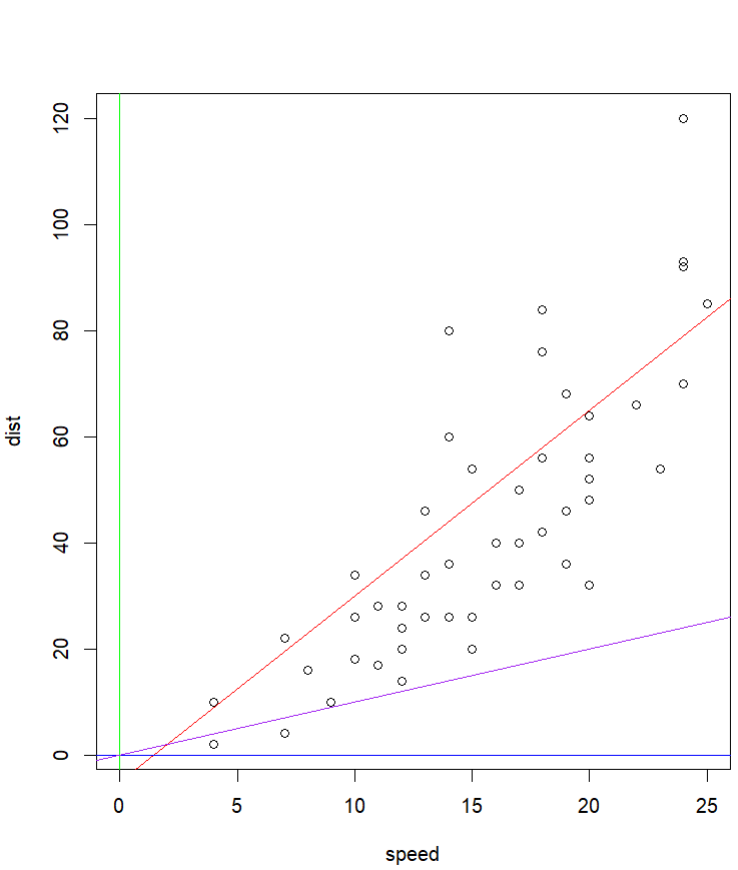
ex2)
# 데이터 생성
x <- c(1, 2, 3, 4, 5)
y <- c(10, 15, 13, 7, 20)
# 그래프 그리기
plot(x, y, type = "b", col = "blue", pch = 19, main = "point_line & abline")
# 그래프에 추가 요소 추가
abline(h = 10, col = "red", lty = 2, lwd = 3) # 가로선 추가
abline(v = 3, col = "green", lty = 3, lwd = 5) # 세로선 추가
legend("topright", legend = "points", col = "blue", pch = 19) # 범례 추가
pie() 함수
- 파이차트를 작성하는 고수준 그래프 함수
- "labels=" 인수를 사용하여 라벨을 표시할 수 있음
- "radius=" 인수를 사용하여 반지름의 크기 정할 수 있음(default: 0.8)
ex)
data <- c(280, 170, 120, 100, 85) # 매출액(억 원)
pie(data) # 파이 차트 작성
lbls <- c("서울", "부산", "경북", "전남", "충청")
pct <- round(data/sum(data)*100) # 백분율 계산
lbls <- paste(lbls, pct) # 라벨(labels)에 백분율(pct) 추가
# paste("서울", 37) → "서울 37" 이런 식으로 문자열을 합침.
lbls <- paste(lbls,"%",sep="") # 라벨(labels)에 % 추가
pie(data, labels=lbls, radius=1.0) # 레이블 포함 파이 차트
hist() 함수
- 히스토그램을 작성하는 고수준 그래프 함수
- "freq=FALSE"을 사용할 경우 세로축 제목이 빈도가 아닌 밀도(density)로 표시
(freq = TRUE (기본값) → 막대 높이 = 빈도, y축 제목은 "Frequency")
- "freq=FALSE"을 사용할 경우 세로축 제목이 빈도가 아닌 밀도(density)로 표시
ex)
hist(cars$speed)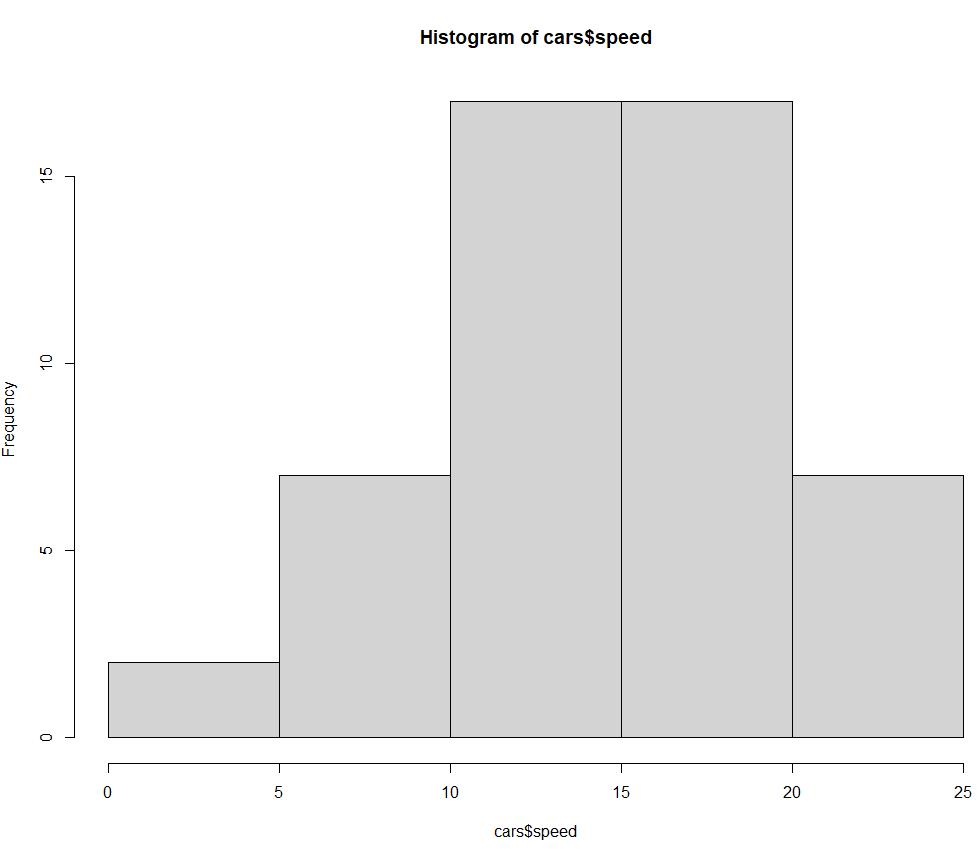
ex II)
x <- rnorm(300, mean=10, sd=2) # 평균이 10, 표준편차가 2인 300개의 난수 샘플을 생성
hist(x) # 히스토그램 작성
hist(x, freq=F) # freq=F: 빈도가 아닌 밀도로 표시
lines(density(x)) # 확률밀도 히스토그램에 선 추가
히스토그램과 막대 그래프의 차이

- 히스토그램은 연속형 데이터를 일정하게 나눈 구간(계급)을 가로 축으로, 각 구간에 해당하는 데이터수(도수)를 세로 축으로 그린 그래프
- 히스토그램을 이용하면 구간별 관측치 분포 상태를 빠르게 확인할 수 있음

그래프 함수들(Summary)

- 막대 그래프: 범주형 데이터의 수량이 많고 적음을 나타낼 때 적합한 그래프
- 상자 그림: 데이터 분포에서 벗어난 극단의 데이터를 판단할 때 적합한 그래프
- 히스토그램: 연속형 데이터를 일정하게 구간을 나누어 각 구간에 해당하는 데이터를 그린 그래프
- 파이 차트: 원을 데이터 범주 구성에 비례에 따라 파이 조각 모양처럼 표현한 그래프
- 줄기 잎 그림: 변수 값을 자릿수로 분류하여 시각화한 그래프, 데이터 전체 형태 파악 가능
- 산점도: 두 변수 간의 관계를 점으로 나타낸 그래프
gapminder 데이터 분석
- gapminder 데이터: 5개 대륙, 총 142개 국가에 대한 1952~2007년의 인구 데이터가 5년 간격으로 담겨 있음
inatall.packages(“gapminder”)
library(gapminder) - 인구 변화를 대륙별로 묶어 관찰
# 개별 국가를 대륙별로 묶어 관찰
y <- gapminder %>% group_by(year, continent) %>% summarize(c_pop=sum(pop))
# 대륙별로 각자 다른 color(col), shape(pch)
plot(y$year, y$c_pop, col=y$continent, pch=c(1:length(levels(y$continent))))
# topleft에 범례를 표시
legend("topleft", legend=levels(y$continent),
pch=c(1:length(levels(y$continent))), col=c(1:length(levels(y$continent))))
- 아시아 대륙의 인구가 특히 급격히 증가하는 추세를 시각적으로 확인함으로써 미래의 경향도 어느 정도 추측해볼 수 있음
- 즉, 시각화된 결과는 직관적인 예측을 유도하는 역할도 함
'R' 카테고리의 다른 글
| [R Lang] 그래프 함수, 회귀 분석 정리 (+ ggplot2 정리 및 연습용 code) (0) | 2025.12.11 |
|---|---|
| [R Lang] 회귀 및 로지스틱 (0) | 2025.11.20 |
| [R Lang] 함수 정리 (데이터 구조 생성 및 확인, 가공 및 처리, 결측치 처리, 구조 변경, 기초 통계 및 수학, 확률 및 난수, 데이터 입출력 및 기타) (0) | 2025.10.24 |
| [R Lang] 기술 통계량 분석, 확률 함수, 외부 데이터 활용 분석 (0) | 2025.10.23 |
| [R Lang] 데이터 결측치, 가공 및 처리, 데이터 구조 변환 (0) | 2025.10.23 |
'R' Related Articles
more



