
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 |
Tags
- 최소 공통 조상
- Delete
- reference counting
- Binary Lifting
- trie
- 비트필드를 이용한 dp
- 그래프 탐색
- 비트마스킹
- Prisma
- 이분 탐색
- Strongly Connected Component
- DP
- PROJECT
- 강한 연결 요소
- 게임 서버 아키텍처
- Overlapped Model
- JavaScript
- select 모델
- Github
- 자바스크립트
- 2-SAT
- 벨만-포드
- map
- ccw 알고리즘
- HTTP
- SCC
- Lock-free Stack
- Behavior Design Pattern
- 트라이
- Spin Lock
Archives
- Today
- Total
dh_0e
[R Lang] 회귀 및 로지스틱 본문
머신러닝과 데이터 마이닝(Data Mining)
- 대부분 같은 방법을 사용함
- 컴퓨터 과학에서는 머신러닝이라고 하고, 통계학에서는 데이터 마이닝 용어를 더 많이 사용
- 데이터 마이닝: 가지고 있는 데이터에서 형상 및 특성을 발견하는 것이 목적
- 머신러닝: 기존 데이터를 통해 학습을 시킨 후 새로운 데이터에 대한 예측값을 알아내는 데 목적을 둠
회귀분석(regression ananlysis)
- 두 요인 간의 인과관계를 파악해 미래를 예측하고 설명하는 대표적인 데이터 분석 기법
- 두 요인
- 독립변수(independent variable): 예측하고자 하는 결과의 원인으로 가정한 변수
- 종속변수(dependent variable): 독립변수가 원인이 돼 예측할 수 있는 결괏값
- 두 요인
- 골턴의 '평균으로의 회귀'에서 유래됨
- 평균으로의 회귀: 키가 아주 큰 아버지의 자식은 아버지보다 크지 못하며 오히려 평균에 가까운 값을 가졌으며, 키가 아주 작은 아버지의 자식은 아버지보다 작지 않고 평균에 가까워지는 평균으로의 회귀하는 특성을 공표
- 독립변수: 아버지의 키
- 종속변수: 아버지의 키에 영향을 받은 아들의 키
- 이처럼 모든 현상이 평균으로 회귀하려는 사실에 기초한 분석이 회귀분석
- 평균으로의 회귀: 키가 아주 큰 아버지의 자식은 아버지보다 크지 못하며 오히려 평균에 가까운 값을 가졌으며, 키가 아주 작은 아버지의 자식은 아버지보다 작지 않고 평균에 가까워지는 평균으로의 회귀하는 특성을 공표
- 종류
- 단순 회귀(simple regression): 독립변수의 수가 하나인 경우
- 다중 회귀(multiple regression): 독립변수의 수가 두 개 이상인 경우
R을 이용한 단순 선형 회귀 분석(Simple Linear Regression Analysis)
- 두 변수 간의 관계식을 도출하는 분석 기법
- lm() 함수를 이용해 두 변수 간의 p-value, 절편과 기울기를 구함
- lm() 함수: linear model 약어
- 절편(intercept): 직선이 x축이나 y축과 만나는 좌표
- 기울기(scope): 직선의 경사도, 값이 클수록 선이 경사지게 표현

- 반응값(종속변수, Y)과 인자(독립변수, X)의 함수 관계를 찾음
- 도출된 회귀 방정식을 통해 예측, 최적화, 인자선별과 같은 분석이 가능
- lm(): 단순 선형 모형으로 적합시키는 함수
- lm(종속변수 ~ 독립변수, data=데이터셋)

- 추정된 회귀식이 dist = -17.579 + 3.932 × speed라는 뜻
- 다음과 같이 표로 나타내보면
plot(cars)
abline(lm(dist~speed, data=cars))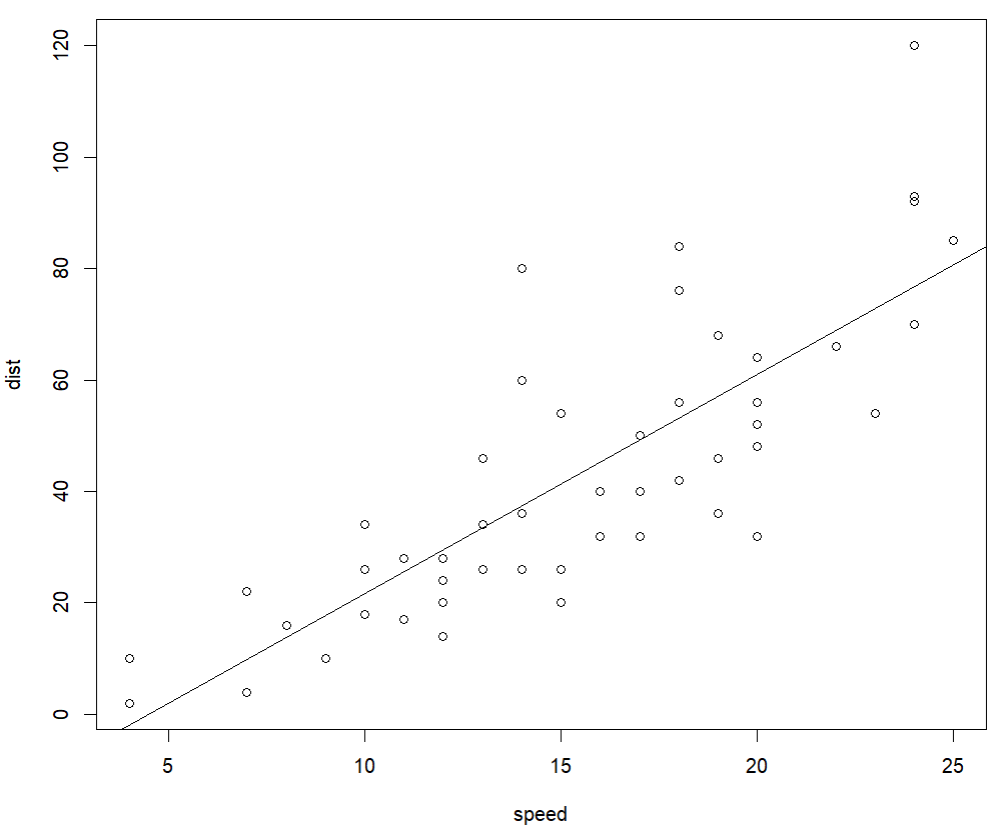

-
- cor.test(테이블명$변수명1, 테이블명$변수명2)
- 상관관계가 있으면 cor 값이 1(양의 상관관계) or -1(음의 상관관계)로 나타남
- 0에 가까울수록 두 변수 간의 상관관계가 없음을 의미



- coef: 회귀 결과에서 계수만 추출
- 다음과 같이 계수를 추출하여 결과 값을 예측해 볼 수 있음
model <- lm(dist~speed, cars)
b <- coef(model)[1]
W <- coef(model)[2]
speed <- c(30, 35, 40)
dist <- W*speed + b
dist
# [1] 100.3932 120.0552 139.7173
- Call: lm(formula = cars)
- 어떤 모델을 돌렸는지: cars 데이터로 단순선형회귀를 했다
- Residuals: 잔차(실제값 - 예측값)의 요약 통계
- Min(최소 잔차): -7.5293
- 1Q(1사분위수): -2.1550
- Median(중앙값): 0.3741
- 3Q(3사분위수): 2.4377
- Max(최대 잔차): 6.4179
- 잔차들이 0 근처에서 대칭으로 퍼져 있으면 모형이 크게 틀어지진 않았다는 분위기

- Coefficients: (계수 표)
- Estimate(추정된 계수 값): 8.28391
- dist=0일 때 예측 speed는 약 8.28
- 직선의 절편
- Std. Error = 0.87438
- t value = 9.474
- Pr(>|t|) = 1.44e-12
- "절편이 0이다"라는 귀무가설을 거의 확실히 기각
- 귀무가설: 차이가 없다고 가정하는 가설
- dist
- Estimate=0.16557
- 제동거리(dist)가 1 증가할 때 speed가 평균적으로 약 0.166만큼 증가하는 것으로 추정
- Std. Error = 0.01749
- t value = 9.464
- Pr(>|t|) = 1.49e-12
- “dist의 계수가 0이다”는 가설을 매우 강하게 기각
- Estimate=0.16557
- 즉 dist는 speed와 통계적으로 유의한 선형 관계가 있다.
- Estimate(추정된 계수 값): 8.28391
- Signif. codes: p값에 따라 별표 몇 개 찍을지 규칙을 보여주는 안내표 (***이면 0.001보다 훨씬 작다는 뜻)
- Residual standard error: 3.156 on 48 degrees of freedom
- 잔차의 표준편차 추정값이 3.156 / 자유도 48은 데이터 50개에서 계수 2개(절편, 기울기)를 빼서 나온 값
- Multiple R-squared: 0.6511
- speed의 변동 중 약 65.1%를 dist가 설명한다는 뜻
- Adjusted R-squared: 0.6438
- 변수 개수를 보정한 $R^{2}$. 단순회귀라 큰 차이는 없음
- F-statistic: 89.57 on 1 and 48 DF, p-value: 1.49e-12
- p-value: 두 변수 간 상관관계가 통계적으로 의미가 있는지 판단하는 수치
- 일반적으로 0.05보다 작을 때 '통계적으로 유의하다'라고 해석
- 작을수록 좋음
- p값이 1.49e-12로 매우 작으므로 이 선형모형 전체가 의미 있다고 알 수 있음
- p-value: 두 변수 간 상관관계가 통계적으로 의미가 있는지 판단하는 수치
단순선형 회귀분석의 목표
- 독립변수(x)와 종속변수(y) 사이의 선형관계를 파악하고 이를 예측에 활용하는 통계적 방법
- ex) 예상 dist, 실제 dist, 오차 구하기
speed <- cars[,1]
pred <- W*speed + b
compare <- data.frame(pred, cars[,2], pred-cars[,2])
colnames(compare) <- c('예상dist', '실제dist', '오차')
head(compare)
R에서의 회귀모델 표기법
- y ~ x 형태로 씀
- 앞에 오는 것이 종속변수(y), 뒤에 오는 것이 독립변수(x)
- ex) dist ~ speed = dist를 speed로 예측
- plot()에서의 사용
- 같은 ~ 표기법을 산점도에도 사용 가능
- ex) plot(dist ~ speed, data=cars) = x축: speed, y축: dist인 산점도가 그려짐
다중변수 데이터 탐색 (산점도)
- 다중변수 데이터는 변수들의 개별 분석보다 변수 간의 관계를 찾는 것이 더 중요
- 산점도(Scatter Plot): plot() 함수나 pairs() 함수를 사용하여 변수 간의 관계를 시각적으로 확인
- pairs(target): 여러 변수들 간의 산점도를 한 번에 그려 관계를 확인하는 데 유용
- 그룹 정보 포함 산점도: 색상(col)이나 점의 모양(pch)을 그룹별로 다르게 표시하여 그룹 간의 관계도 파악할 수 있음
- ex) mtcars 데이터셋에서 자동차의 중량(wt)과 연비(mpg) 사이의 관계
wt <-mtcars$wt # 중량 자료
mpg <- mtcars$mpg # 연비 자료
plot(wt, mpg, # 2개 변수(x축, y축)
main="중량-연비 그래프", # 제목
xlab="중량", # x축 레이블
ylab="연비(MPG)", # y축 레이블
col="red", # point의 color
pch=19)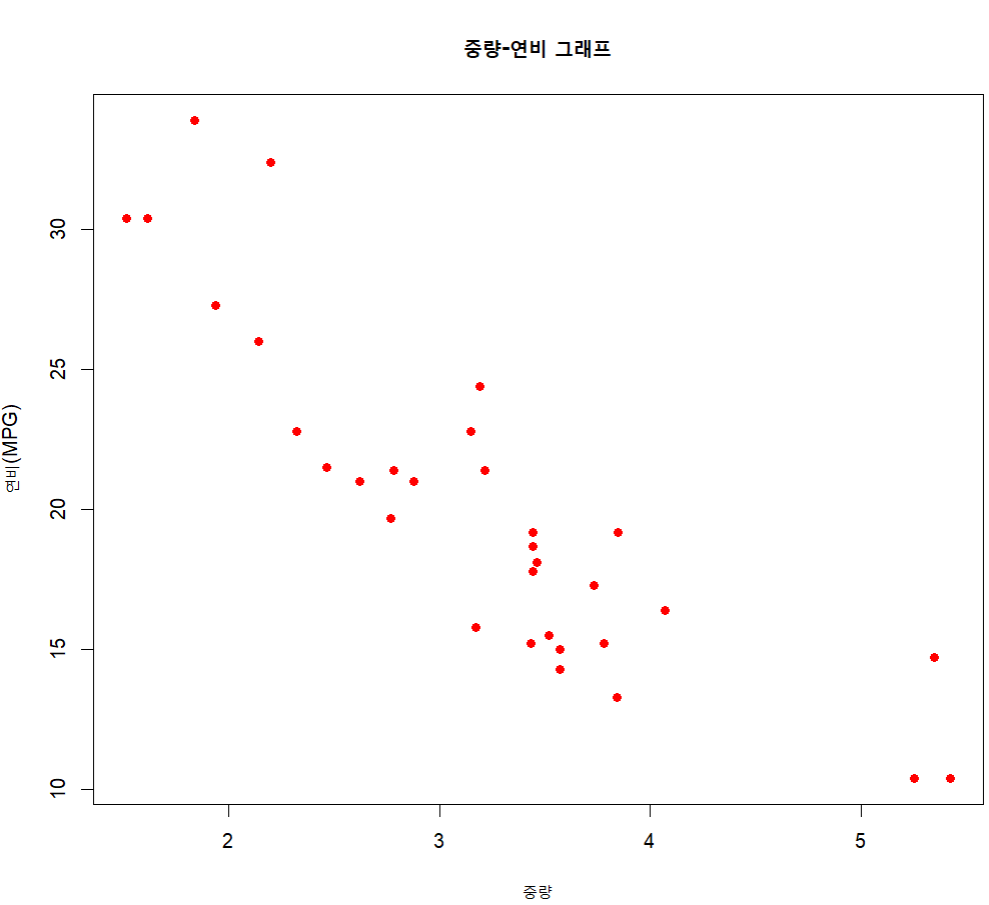
- ex II) 여러 변수(mpg, disp, drat, wt) 간의 산점도 확인
vars <- c("mpg","disp","drat","wt") # 대상 변수
target <- mtcars[,vars]
pairs(target, main="Multi Plots")
ex III) Petal.Length(꽃잎의 길이)와 Petal.Width(꽃잎의 폭)의 산점도
iris.2 <- iris[,3:4] # 데이터 준비
point <- as.numeric(iris$Species) # 점의 모양
color <- c("red","green","blue") # 점의 컬러
plot(iris.2, main="Iris plot", pch=c(point), col=color[point])
legend("topleft", legend = levels(iris$Species), pch = 1:3, col = color)
- Petal.Length(꽃잎의 길이)의 길이가 길수록 Petal.Width(꽃잎의 폭)도 커짐
- setosa 품종은 다른 두 품종에 비해 꽃잎의 길이와 폭이 확연히 작음
- virginica 품종은 다른 두 품종에 비해 꽃잎의 길이와 폭이 제일 큼
상관분석과 상관계수
- 추세의 모양이 선(line) 모양이어서 '선형적 관계'에 있다고 표현
- 선형적 관계라 해도 강한 선형적 관계가 있고, 약한 선형적 관계도 있음
- 상관분석(correlation analysis): 얼마나 선형성을 보이는지 수치상으로 나타낼 수 있는 방법
- 상관계수(correlation coefficient): 상관관계를 수치로 나타낸 -1에서 1 사이의 값
- 상관계수가 0인 경우: 두 변수 X, Y 사이에 상관성을 찾기 어려움
- 상관계수가 (-)인 경우: X, Y가 반비례, 음의 상관관계에 있음
- 상관계수가 (+)인 경우: X, Y가 비례, 양의 상관관계에 있음
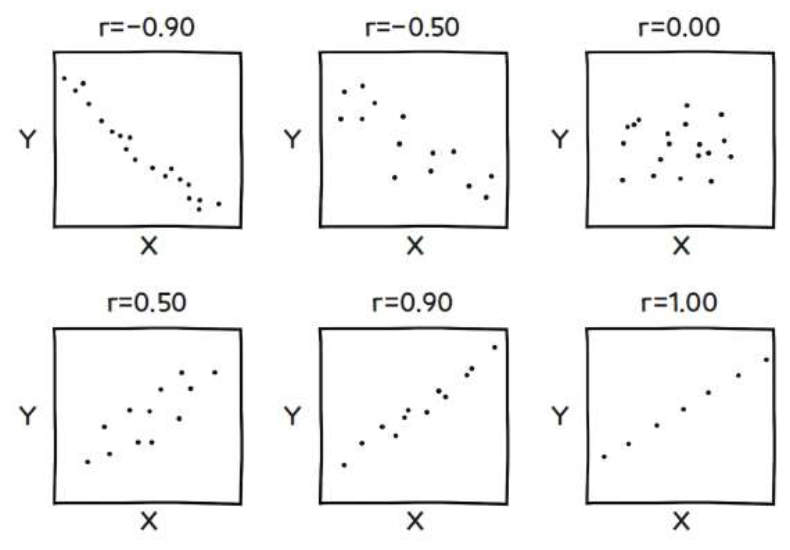
피어슨 상관계수
- 두 변수의 선형 상관관계를 계량화한 수치
- 일반적으로 상관관계는 피어슨 상관관계를 의미함

- -1 ≤ r ≤ 1: 결괏값은 -1과 1 사이에 있음
- r > 0: 양의 상관관계(x가 증가하면 y도 증가)
- r < 0: 음의 상관관계(x가 증가하면 y는 감소)
- r 이 1이나 –1에 가까울수록 x, y의 상관성이 높음


Boston Housing 자료 탐색 실습
- BostonHousing: 미국 보스턴 지역의 주택 가격 정보와 주택 가격에 영향을 미치는 여러 요소들에 대한 정보를 담고 있음
- 총 14개의 변수로 구성이 되어 있는데, 5개의 변수(crim, rm, dis, tax, medv)만 선택하여 분석
- mlbench 패키지에서 제공 - 다양한 기계학습을 위한 데이터가 있는 패키지

- grp 변수 추가
- grp: 주택 가격을 상(H), 중(M), 하(L)로 분류한 것으로 25.0 이상 상, 17.0 이하 하, 나머지를 중으로 분류
install.packages("mlbench")
library(mlbench)
data("BostonHousing")
myds <- BostonHousing[,c("crim", "rm", "dis", "tax", "medv")]
head(myds)
grp <- c()
for(i in 1:nrow(myds)){
if(myds$medv[i]>=25.0){
grp[i] <- "H"
}else if(myds$medv[i]<=17.0){
grp[i] <- "L"
}else{
grp[i] <- "M"
}
}
grp <- factor(grp)
grp <- factor(grp, levels=c("H","M","L"))
myds <- data.frame(myds, grp)
par(mfrow=c(2, 3))
for(i in 1:5){
hist(myds[,i], main=colnames(myds)[i], col="yellow")
}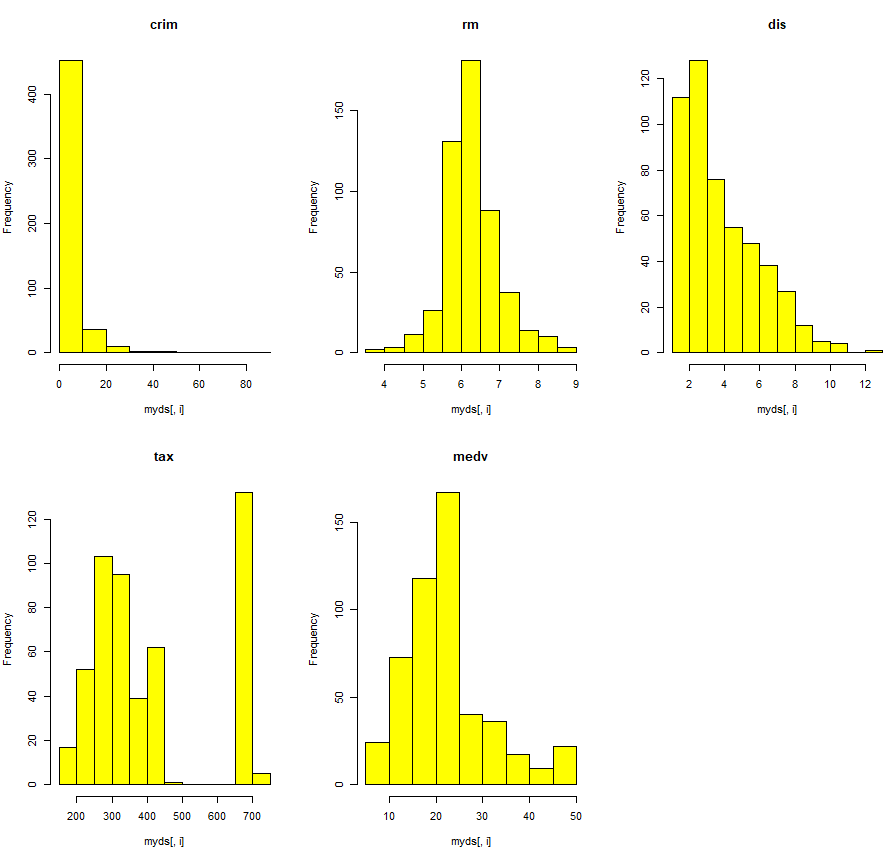
- rm, mdev 변수만 종 모양의 정규분포에 가깝고, crim, dis는 관측값들이 한쪽으로 쏠려서 분포
- tax는 중간에 관측값이 없는 빈 구간이 존재하는 특징을 가짐
boxplot() 함수
- 데이터 분포를 한눈에 보여주는 상자 그림을 작성하는 고급 그래프 함수
- 보여주는 것
- 중앙값: 상자 안에 있는 가운데 가로선
- Q1, Q3: 상자 아래, 위 경계
- 상자의 높이: IQR=Q3-Q1 (데이터가 얼마나 퍼져 있는지)
- 이상치(outlier): 위 범위를 벗어난 값들, 점이나 동그라미로 따로 표시
par(mfrow=c(2, 3))
for(i in 1:5){
boxplot(myds[,i], main=colnames(myds)[i])
}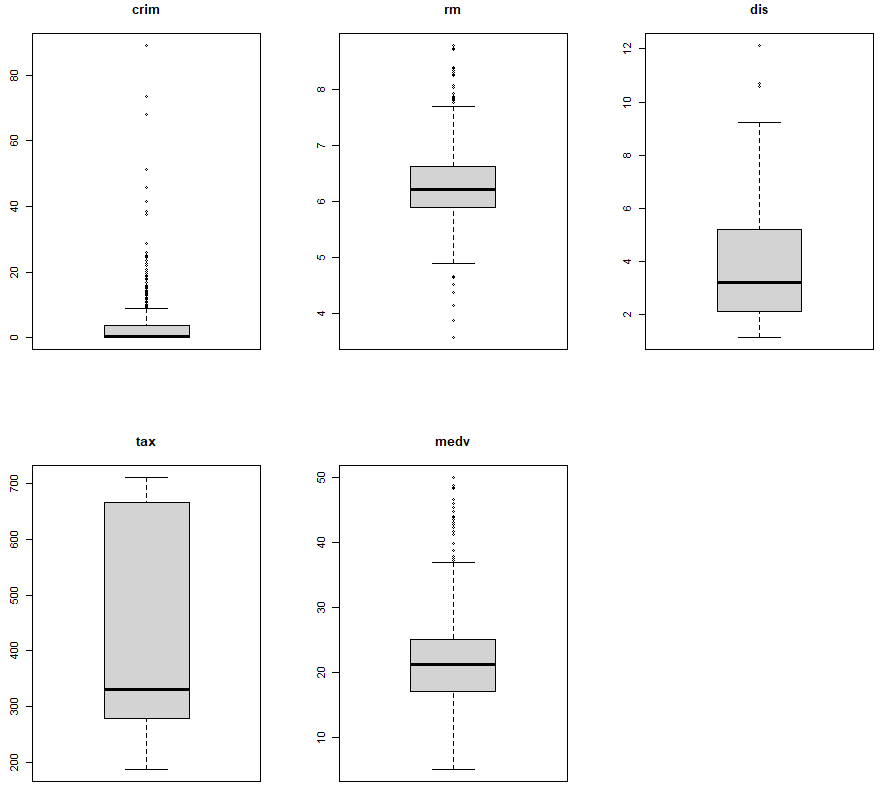
- 1인당 범죄율(crim)은 관측값들이 좁은 지역에 밀집되어 있음(관측값들의 편차가 매우 작음)
- 재산세율(tax)은 넓게 퍼져 있는 것(관측값들의 편차가 비교적 큼)을 확인
boxplot(myds$crim~myds$grp, main="1인당 범죄율")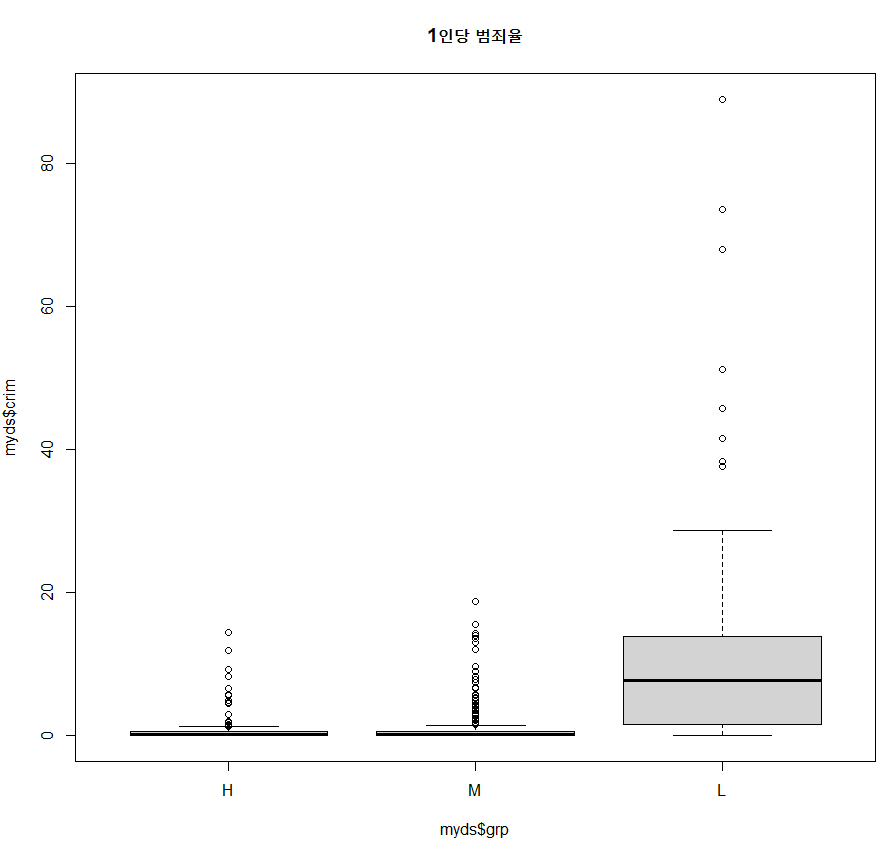
- 주택 가격(grp)이 높은 지역이나 중간 지역의 범죄율(crim)은 낮고, 주택 가격이 낮은 지역의 범죄율이 높게 나타남
boxplot(myds$rm~myds$grp, main="방의 개수")
- 주택 가격(grp)이 높으면 방의 개수(rm)도 많다는 것을 알 수 있음
- 주택 가격이 중간인 지역과 하위인 지역의 방의 개수 평균은 큰 차이가 나지 않음
- 중간 그룹의 방의 개수가 5.2~6.8로 비교적 균일한 반면, 하위 그룹의 방의 개수는 4.5~7.2 사이로 넓게 퍼져있는 것을 알 수 있음
다중 산점도(pairs)를 통한 변수 간 상관관계의 확인
pairs(myds[,-6]) # 6번째 열은 grp로 제외함
- medv(주택 가격)과 양의 상관성이 있는 변수는 rm(가구당 방의 개수)
- crim(1인당 범죄율)은 medv(주택 가격)과 음의 상관성이 있는 것으로 보임
point <- as.integer(myds$grp)
color <- c('red', 'green', 'blue')
pairs(myds[,-6], pch=point, col=color[point])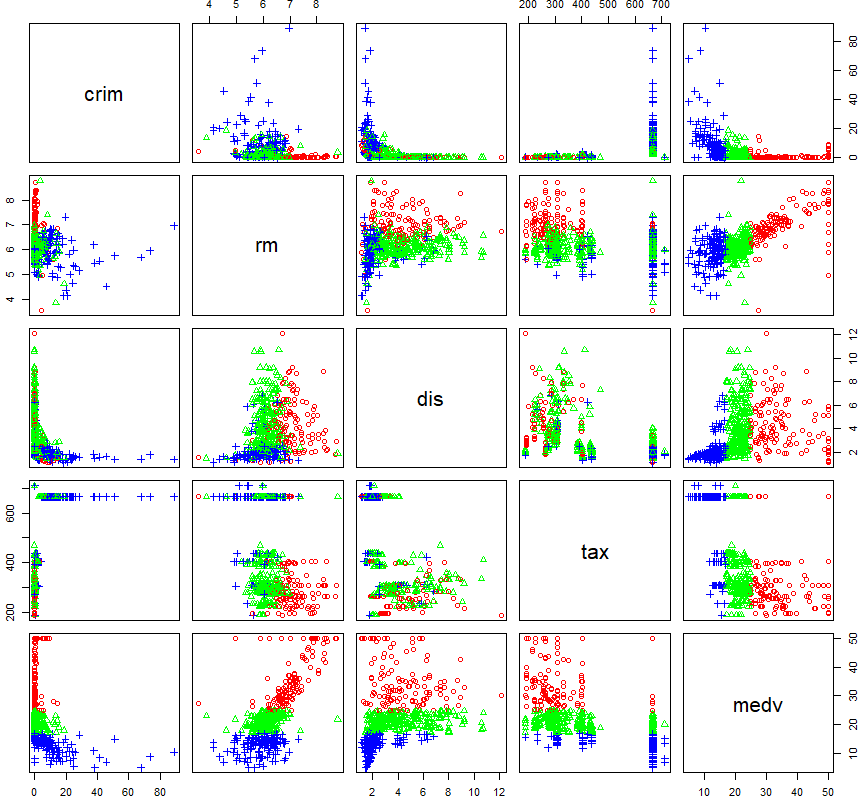
- 산점도에서 그룹별(grp)로 분포 위치가 뚜렷하게 구분
- 주택 가격 중간 그룹(green)은 상위 그룹(red), 하위 그룹(blue)에 비해 주택 가격의 변동폭이 좁음
# 변수 간 상관계수의 확인
cor(myds[,-6])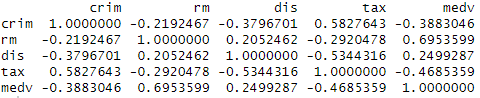
- 분석 결과:
- medv(주택 가격)를 기준으로 보았을 때 상관계수가 가장 높은 것은 rm(가구당 방의 개수)으로 약 0.695
- 산점도상에서 음의 상관성이 높은 것으로 보였던 crim(1인당 범죄율)은 상관계수가 약 -0.388로 실제로는 상관도가 높지 않음
다중선형 회귀모델 만들기
- 단순선형 회귀가 하나의 독립변수를 다룬다면 다중선형 회귀는 여러 개의 독립변수를 다룸
- ex) 키와 몸무게를 가지고 혈당 수치를 예측
- 다중 회귀 모델(다중 회귀식)의 일반적인 형태

- R에서는 다중 회귀모델도 lm() 함수로 구함
Prestige 데이터셋으로 다중선형 회귀모델 만들기
- Prestige 데이터셋: 102개의 관측값과 6개의 변수로 구성됨
- 102개의 직업별로 교육기간, 소득, 여성 비율, 직업 명망도, 직업 유형 등의 데이터 기록
- 교육 기간은 education 변수, 소득은 income 변수에 저장돼 있음
- 교육 기간과 소득과의 관계 분석, 변수의 관계 분석을 시도(직군의 소득을 관련된 변수로 예측)
library(car)
newdata <- Prestige[,c(1:4)]
plot(newdata, pch=16, col="blue", main='Matrix Scatterplot')
mod1 <- lm(income ~ education + prestige + women, data=newdata)
summary(mod1)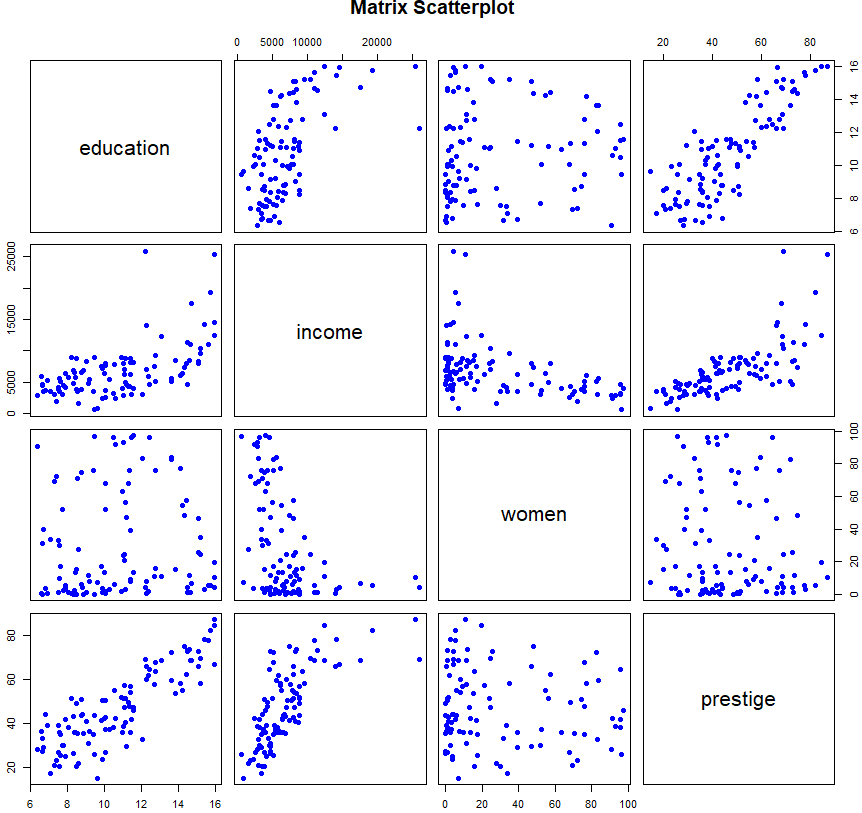


- income ~ education + prestige + women
- 독립변수: income
- 종속변수: education, prestige, women
- 평균교육연수가 9.5년, 여성비율이 20%, 평판도가 80이라면 예상평균 연봉은?
- income=-253.850 + 177.199 * education + 141.435 * prestige - 50.896 * women
= -253.850 + 177.199 * 9.5 + 141.435 * 80 + 50.896 * 20
= 13762.26
- income=-253.850 + 177.199 * education + 141.435 * prestige - 50.896 * women

- ①에 *: 해당 변수가 종속변수를 설명하는 데 얼마나 중요한 변수인가를 나타냄(*가 많을수록 통계적으로 중요하다는 의미)
- ②에 p-value(유의 수준) 값: 구한 회귀모델이 의미 있는 모델인지(신뢰할 수 있는 모델인지)를 나타내는 것으로, 이 값이 작을수록 의미 있는 모델인 것을 나타냄
- ③에 Adjusted R-squared 값: 모델의 설명력을 나타내며 0~1 사이의 값을 가짐
# 예상 수입, 실제 수입, 오차 구하기
pred <- predict(mod1, Prestige[,c('education', 'prestige', 'women')])
pred
pred[order(pred, decreasing=T)]
compare <- data.frame(pred, Prestige[,2], pred-Prestige[,2])
colnames(compare) <- c('예상', "실제", "오차")
head(compare)
다중선형 회귀모델에서 변수의 선택
- 다중선형 회귀모델에서는 종속변수를 설명하는 데 도움 되는 독립변수가 다수 존재
- 하지만 모든 독립변수가 종속변수를 설명하는 데 동일하게 기여하는 것은 아님
- 어떤 변수는 기여도가 높고, 어떤 변수는 기여도가 낮음
- ex) 수면시간, 학습시간은 성적을 예측하는 데 중요한 기여를 할 수 있지만, 점심식사 여부는 성적을 예측하는 데 별로 도움이 되지 않는 변수
- 오컴의 면도날 법칙: 기여도가 낮거나 거의 없는 변수들은 모델에서 제외하는 것이 좋음
(적은 변수를 가지고 현실을 잘 설명할 수 있는 것이 좋은 모델이기 때문)
stepAIC() 함수
- R에서는 모델에 기여하는 변수들을 선별할 수 있는 단계적 회귀함수를 제공 (독립변수를 자동으로 찾음)
- 모든 독립변수가 종속변수 설명을 기여하지 않음 (기여도가 낮은 변수를 제외함)
library(MASS) # stepAIC( ) 함수 제공
newdata2 <- Prestige[,c(1:5)] # 모델 구축에 사용할 데이터셋 생성
head(newdata2)
mod2 <- lm(income ~ education + prestige + women + census, data= newdata2)
summary(mod2) # 다중회귀모델
mod3 <- stepAIC(mod2) # 변수 선택 진행
mod3 # 변수 선택 후 결과 확인
summary(mod3) # stepAIC() 적용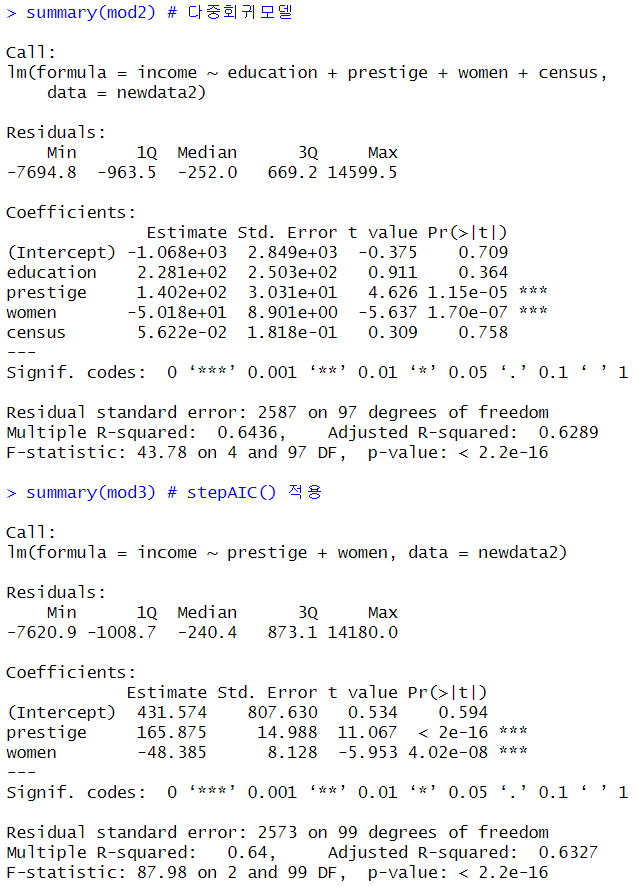
로지스틱 회귀분석의 개념
- 로지스틱 회귀(logistic regression): 회귀모델에서 종속변수의 값의 형태가 연속형 숫자가 아닌 범주형 값인 경우를 다루기 위해서 만들어진 통계적 방법
- ex) iris 데이터셋에서 4개의 측정값을 가지고 품종(범주형 값)을 예측
- R에서 로지스틱 회귀 모델은 glm() 함수 이용
iris.new <- iris
iris.new$Species <- as.integer(iris.new$Species) # 범주형 자료를 정수로 변환
head(iris.new)
mod.iris <- glm(Species ~., data=iris.new) # 로지스틱 회귀모델 도출
summary(mod.iris) # 회귀모델의 상세 내용 확인- Species ~.,: 회귀모델에서 종속변수가 Species이고, 나머지 변수들은 모두 독립변수라는 뜻
- 나머지 4개 변수(Petal.Length, Petal.Width, Sepal.Length, Sepal.Width)를 전부 독립변수로 쓰는 모델

로지스틱 회귀모델을 이용한 예측
- 수작업으로 계산하여 품종을 예측하는 방법 대신, 구해 놓은 회귀모델을 이용하여 보다 편리한 방법으로 품종을 예측
- predict(모델객체, newdata=새_데이터프레임, type=...)
- 모델 객체: lm, glm 같은 걸로 미리 학습해둔 회귀 모델
- newdata: 예측에 쓸 설명변수(독립변수)만 들어 있는 data.frame
- type: 회귀가 default라 안 써도 됨, 분류/로짓이면 "response" 등 지정
# 예측 대상 데이터 생성(데이터프레임)
unknown <- data.frame(rbind(c(5.1, 3.5, 1.4, 0.2))) # rbind 대신 t() 써도 됨
names(unknown) <- names(iris)[1:4]
unknown # 예측 대상 데이터
pred <- predict(mod.iris, unknown) # 품종 예측
pred # 예측 결과 출력
round(pred,0) # 예측 결과 출력(소수 첫째 자리에서 반올림)
# 실제 품종명 알아보기
pred <- round(pred,0)
pred
levels(iris$Species)
levels(iris$Species)[pred]
- 다수의 데이터에 대한 예측 "mean(pred==answer)"
test <- iris[,1:4] # 예측 대상 데이터 준비
pred <- predict(mod.iris, test) # 모델을 이용한 예측
pred <- round(pred,0)
pred # 예측 결과 출력
answer <- as.integer(iris$Species) # 실제 품종 정보
pred == answer # 예측 품종과 실제 품종이 같은지 비교
acc <- mean(pred == answer) # 예측 정확도 계산
acc # 예측 정확도 출력
'R' 카테고리의 다른 글
| [R Lang] 특이 행렬, 조건문, 반복문, 날짜 함수 (0) | 2025.12.11 |
|---|---|
| [R Lang] 그래프 함수, 회귀 분석 정리 (+ ggplot2 정리 및 연습용 code) (0) | 2025.12.11 |
| [R Lang] 그래프 함수 I (1) | 2025.11.17 |
| [R Lang] 함수 정리 (데이터 구조 생성 및 확인, 가공 및 처리, 결측치 처리, 구조 변경, 기초 통계 및 수학, 확률 및 난수, 데이터 입출력 및 기타) (0) | 2025.10.24 |
| [R Lang] 기술 통계량 분석, 확률 함수, 외부 데이터 활용 분석 (0) | 2025.10.23 |
'R' Related Articles
more



