
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 |
Tags
- 게임 서버 아키텍처
- statefulset
- DP
- Strongly Connected Component
- 비트필드를 이용한 dp
- Behavior Design Pattern
- 최소 공통 조상
- JavaScript
- Spin Lock
- reference counting
- SCC
- Prisma
- 강한 연결 요소
- trie
- ccw 알고리즘
- 그래프 탐색
- 이분 탐색
- 트라이
- Github
- HTTP
- 벨만-포드
- 자바스크립트
- map
- Delete
- Overlapped Model
- PROJECT
- Lock-free Stack
- select 모델
- Binary Lifting
- 2-SAT
Archives
- Today
- Total
dh_0e
[Cloud] HPA (Horizontal Pod Autoscaling) 본문
Pod의 AutoScaling 방법
- 운용 중인 Pod의 서비스 상황에 따라 Pod의 수 또는 Pod에 할당된 리소스의 양을 자동으로 조정
- 수요변화와 서비스 품질등을 고려하여 적정하게 자동으로 스케일링

- HPA(Horizontal Pod Autoscaler, 수평 스케일링)
- Pod의 개수를 늘리거나(out) 줄임(in)
- Scale out, Scale in
- VPA(Vertical Pod Autoscaler, 수직 스케일링)
- 해당 워크로드를 위해 이미 실행 중인 Pod에 더 많은 자원(메모리, CPU) 할당(up) 또는 해제(down)
- Scale up, Scale down
HPA (Horizontal Pod Autoscaler)
- 개념
- Application의 부하에 따라 Deployment나 ReplicaSet 등에 적용하여 포함된 Pod 수를 자동으로 조정
- CPU 사용률, 메모리 사용량, 사용자 정의 메트릭 등 특정 메트릭 기반
- 메트릭: 시스템 상태를 수치로 나타낸 값 (예: CPU 사용률, 메모리 사용량, 초당 요청 수(RPS) 등)
- ex) 부하가 늘어나면 Pod를 일시적으로 늘리고, 부하가 줄어들면 다시 Pod의 숫자를 줄여 서버 내 자원을 효율적으로 관리
- Metric 종류
- 리소스 메트릭: CPU 사용률과 메모리 사용률을 모니터링하여 스케일링 결정
- 사용자 정의 메트릭: Application 요구에 맞게 정의한 메트릭
- ex) HTTP 요청 수, 응답 시간 등
- 외부 메트릭: Kubernetes 외부에서 수집된 메트릭
- ex) 외부 API 응답 시간, 클라우드 서비스 제공자의 서비스 사용량 등

- 장점
- 서비스 품질 향상
- 비용 관리 향상
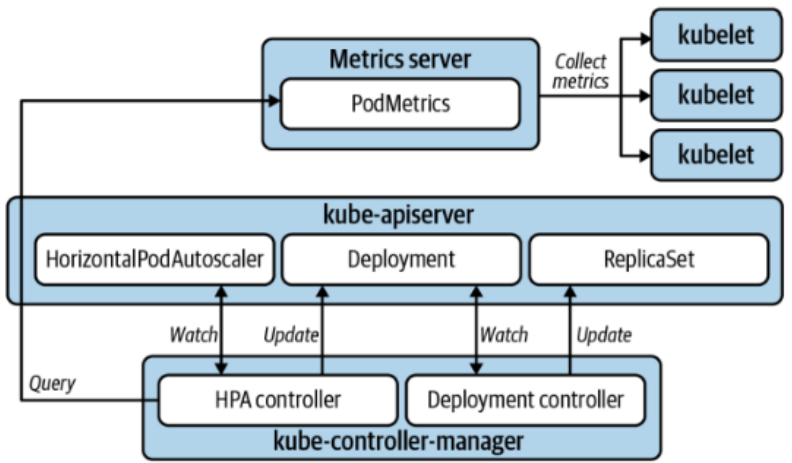
- 메트릭 서버: Kubelet으로부터 메트릭을 가져옴
- HPA 컨트롤러: 15초마다 메트릭 서버에서 메트릭을 조회
- HPA 컨트롤러: 원하는 복제본 수를 계산함
- HPA 컨트롤러: API 서버를 통해 관련 Deployment를 업데이트
- Deployment 컨트롤러: 이를 처리하여 ReplicaSet을 업데이트, 그 결과로 Pods의 수가 변경

- Metrics Server는 K8s 클러스터에서 CPU 및 메모리와 같은 메트릭 데이터를 수집하고, 클러스터 운영 및 오토 스케일링(HPA, VPA)에 필요한 실시간 모니터링 정보를 제공해 줌
- HPA와 VPA와 같은 오토스케일러는 직접 Pod 상태를 보는 것이 아니라, API Server를 통해 제공되는 메트릭 정보를 읽어서 스케일링 여부를 결정함
HPA 구동방법
- "kubectl autoscale" 명령을 통해 horizontalPodAutoscaler(HPA) 생성
- 또는 yaml 파일로 kubectl apply -f 해서 배포 가능
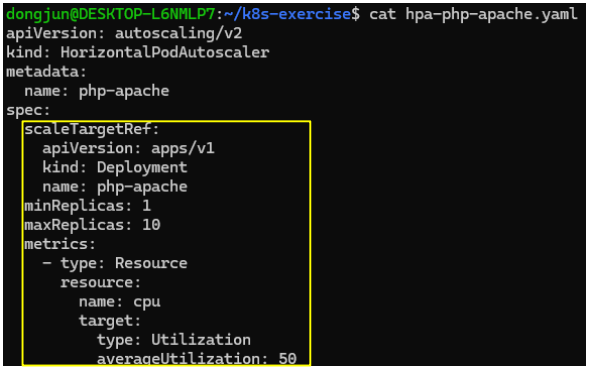
- min, maxReplicas: 스케일링 시에 최대, 최소 Replica 개수
- metrics.type: 어떤 타입의 metric 인지
- metrics.resource
- name: metric 종류
- target: 어떤 조건에서 스케일링하는지
- averageUtilization(cpu 혹은 memory 사용량)이 50%가 되면 Scale up
- 현재 resource.name이 cpu이므로 cpu 사용령이 50%가 되면 Scale up
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 50
- type: Resource # 메모리 조건 추가
resource:
name: memory
target:
type: Utilization
averageUtilization: 60 # 메모리가 60%를 넘을 때- CPU와 Memory를 모두 감시하기 위한 yaml 파일의 metrics
- 위와 같이 설정하면, CPU가 50%를 넘거나, 메모리가 60%를 넘을 때 HPA 작동
HPA 작동 방식
- 메트릭 모니터링
- 일정 주기(Default: 15s)마다 CPU 사용량, 메모리 사용량, 커스텀 메트릭 or 외부 메트릭을 모니터링
- Kubernetes API 서버에 등록된 메트릭 서버나 외부 모니터링 도구를 통해 수집
- 외부 모니터링 도구 ex) 외부 API 응답 시간(Kubernetes와 직접 연관되지 않은 외부트래픽에 따른 값)
- 임계값 평가
- HPA는 목표 메트릭 값(Target Metric)과 현재 메트릭 값을 비교하여 임계값 초과 여부를 평가
- ex 1) 목표 CPU 사용률이 60%로 설정된 경우, 현재 CPU 사용률이 70%를 넘는다면 Scale out이 필요하다고 판단
- ex 2) 현재 CPU 사용률이 50%라면 Scale in이 필요하다고 판단
- HPA는 목표 메트릭 값(Target Metric)과 현재 메트릭 값을 비교하여 임계값 초과 여부를 평가
- Pod 스케일링
- 측정된 메트릭 값이 임계값을 초과하면 HPA는 Pod 수를 늘려서 부하를 분산
- 측정된 메트릭 값이 임계값 이하로 떨어지면 불필요한 Pod 수를 줄여 리소스 낭비를 방지
- 목표 메트릭 값 대비 현재 메트릭 값의 비율을 계산하여 Pod 수 결정

- n%의 기준점
- HPA가 "CPU 사용량이 50%에 도달했다"라고 판단하려면 전체 100%가 얼마인지 아는 기준점이 필요
- Deployment(php-apache) 안의 Pod 설정 중 resources.requests.cpu에 할당된 값을 기준으로 계산
- Downward API로 확인할 수 있었음

- resources: 필드
- 각 컨테이너에 대한 리소스 요청 및 제한 정의
- limits:
- 컨테이너가 사용할 수 있는 리소스의 최대치
- "cpu: 500m"는 컨테이너가 최대 500밀리 코어(0.5 코어)의 CPU를 사용할 수 있도록 제한
- requests:
- 컨테이너가 기본적으로 필요한 리소스의 양
- HPA는 request 값을 기준으로 CPU target 사용량(%)을 설정
HPA 급격한 변화 방지

- 메트릭 변동으로 인해 Pod 수가 급격하게 변동하는 것을 방지하기 위한 scaleDwon 동작 설정

- 메트릭 변동으로 인해 Pod 수가 급격하게 변동하는 것을 방지하기 위한 시간 범위 설정
- 스케일링을 수행하기 전, 지정된 윈도우 동안 수집된 메트릭 값 중 가장 높은 값을 사용하여 스케일링 여부를 결정
- 위 예시) 300s 동안 수집된 메트릭 값 중 가장 높은 값을 사용
- 불필요한 스케일 다운을 방지하고, 안정성을 유지할 수 있음
통합 예시

'Cloud > Kubernetes' 카테고리의 다른 글
| [Cloud] Service Routing & Pod Networking (CNI Plugin) (0) | 2026.06.07 |
|---|---|
| [Cloud] Pod(Application) Update 종류 및 실습 (0) | 2026.06.03 |
| [Cloud] StatefulSet (0) | 2026.06.03 |
| [Cloud] Kubernetes Volumes III (Downward API, Job, CronJob, DaemonSet) (0) | 2026.05.08 |
| [Cloud] Kubernetes Volumes II (Storage Class, ConfigMap, Secret) (0) | 2026.05.04 |
'Cloud/Kubernetes' Related Articles
more



