
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 |
Tags
- 게임 서버 아키텍처
- 비트필드를 이용한 dp
- Overlapped Model
- Delete
- 벨만-포드
- 자바스크립트
- PROJECT
- 트라이
- Strongly Connected Component
- 최소 공통 조상
- 강한 연결 요소
- ccw 알고리즘
- Github
- Spin Lock
- SCC
- Binary Lifting
- trie
- map
- select 모델
- Lock-free Stack
- 2-SAT
- statefulset
- reference counting
- JavaScript
- 이분 탐색
- DP
- Behavior Design Pattern
- 그래프 탐색
- Prisma
- HTTP
Archives
- Today
- Total
dh_0e
[Cloud] Service Routing & Pod Networking (CNI Plugin) 본문
Service & Endpoints

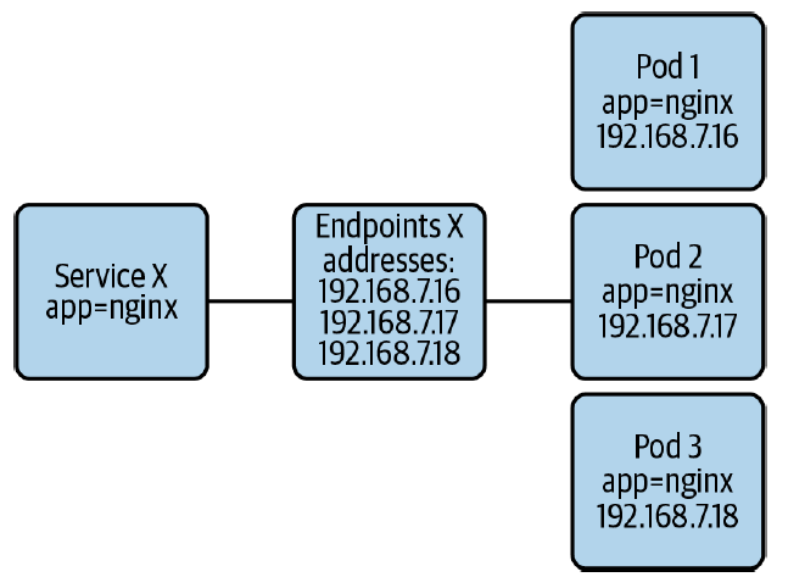
- ClusterIP(Frontend): 쿠버네티스 내부에서만 사용하는 가상의 IP 주소
- Backend pool: 서비스 조건(Pod Selector)에 들어맞는 실제 파드들의 묶음
- Endpoints
- 서비스가 생성될 때 쿠버네티스가 자동으로 만들어주는 객체 (Master Node 안에 존재)
- 트래픽을 넘겨받을 '실제 파드들의 IP 주소 목록'을 보관함
- Endpoints Controller: 파드들의 상태(Ready condition)를 지속적으로 감시하여, 트래픽을 받을 준비가 된 건강한 Pod들의 IP 목록만을 Endpoints 객체에 최신 상태로 유지해 주는 관리자 역할
- Q: Master Node 내부의 endpoints에는 private 주소가 담겨있는데, 어떻게 이것만 보고 Pod를 찾아갈 수 있는지? 라우터가 있는 건지?
- A: Master Node는 Endpoints라는 주소록 데이터만 보관하고 있을 뿐, 실제로 Pod를 찾아가서 트래픽을 꽂아주진 않음. 라우터 역할을 실질적으로 수행하는 것은 각 노드(Worker Node 포함)에 설치된 Kube-proxy와 CNI 플러그인(Calico, Cilium 등)으로 다음과 같은 순서로 패킷을 전달함
- Master Node 안에서 동작하는 Endpoint Controller가 Pod들의 상태를 감시하며 건강한 Pod들의 Private IP 목록을 수집하여 Endpoints라는 객체로 만들고 API 서버에 저장
- 클러스터를 구성하는 모든 노드에는 Kube-proxy라는 에이전트가 항상 실행되고 있음. 이 kube-proxy들이 API 서버를 계속 보고 있다가, Endpoints가 업데이트되면 그 정보를 자기 노드로 가져옴
- kube-proxy는 자기가 속한 노드의 리눅스 커널에 다음과 같은 규칙을 작성
- "클라이언트가 Service IP로 요청을 보내면, 방금 Master Node에서 받아온 Pod의 Private IP(Endpoints) 중 하나로 목적지를 바꿔라"
- CNI는 BGP 라우팅 프로토콜을 사용해 노드끼리 본인 노드의 Pod 대역을 알려주며 경로를 서로 학습하게 만들거나, VXLAN 같은 캡슐화/터널링 기술을 써서 Private IP 패킷을 실제 물리 노드의 IP 패킷으로 감싸서 안전하게 다른 노드로 배달해 줌
- 각 노드에 존재하는 CNI(Container Network Interface) 플러그인은 Pod 네트워크를 구성하고 라우팅 경로를 전파하는 등, 실질적인 라우터와 네트워크 스위치의 역할을 수행함
Kube-proxy
- 정의: 클러스터의 모든 노드에서 실행되는 네트워크 에이전트
- 현재는 거의 CNI 플러그인에 대체됨
- 3가지 작동 모드를 지원함
1. Iptables 모드 (기본값)

- Kube-proxy의 기본 동작 모드로, 리눅스 커널의 NAT(DNAT) 기능을 활용함
- DNAT(목적지 주소 변환): 클라이언트가 패킷을 ClusterIP로 보내면, iptables 규칙이 그 패킷의 목적지 IP를 서비스 IP에서 실제 Pod의 IP로 바꿔치기하여 전달 (하단 그림 참고)
- NodePort나 LoadBalancer 방식도 포트 번호를 기준으로 비슷한 규칙을 사용함

- 성능 한계
- 클러스터 내의 서비스(Pod) 개수가 늘어날수록 iptables 규칙 목록도 선형적으로 길어져 성능이 저하됨
- 업데이트가 발생할 때마다 전체 테이블을 새로 덮어써야 해서 시간이 오래 걸림
2. IPVS(IP Virtual Server) 모드

- 리눅스 커널에 내장된 고급 로드밸런싱 기술
- 리스트를 위에서부터 훑어보는 iptables와 달리 해시 테이블을 사용하여 목적지 Pod를 즉시 찾아내기 때문에 대규모 환경에서도 속도가 매우 빠름
- Service IP 주소(key) : 목적지 Pod 주소 (value)
3. Userspace(CNI를 통한 완전 대체)
- 최신 트렌드에서는 Kube-proxy 자체를 아예 빼버리고, Cilium 같은 고급 CNI 플러그인이 라우팅을 직접 통제하기도 함
- Cilium: 리눅스 커널의 강력한 도구인 eBPF를 사용하여 데이터 플레인 수준에서 트래픽을 처리하며, 이 역시 해시 테이블을 사용해 초고속으로 endpoints를 찾아냄
K8S Networking Considerations
- K8s의 모든 Pod들은 NAT 없이 단일 네트워크처럼 작동하게끔 함
- Pod 간 통신을 위해 구성해야 할 5가지 핵심 요소가 있음
1. IPAM(IP Address Management): 클러스터 내부의 Pod들에 IP를 할당하는 메커니즘
- 클러스터를 초기화할 때 전체 IP 대역(CIDR)을 설정하며, 개별 노드는 이 전체 대역 중 일부(기본적으로 /24 크기)를 쪼개어 할당받아 사용
- CIDR(Classless Inter-Domain Routing): 유연하게 IP 주소를 할당하고 관리하기 위해 사용되는 표준 IP 주소 표기 및 분류 방식 ("IP 주소/서브넷 마스크"로 표기하는 분류 방식)
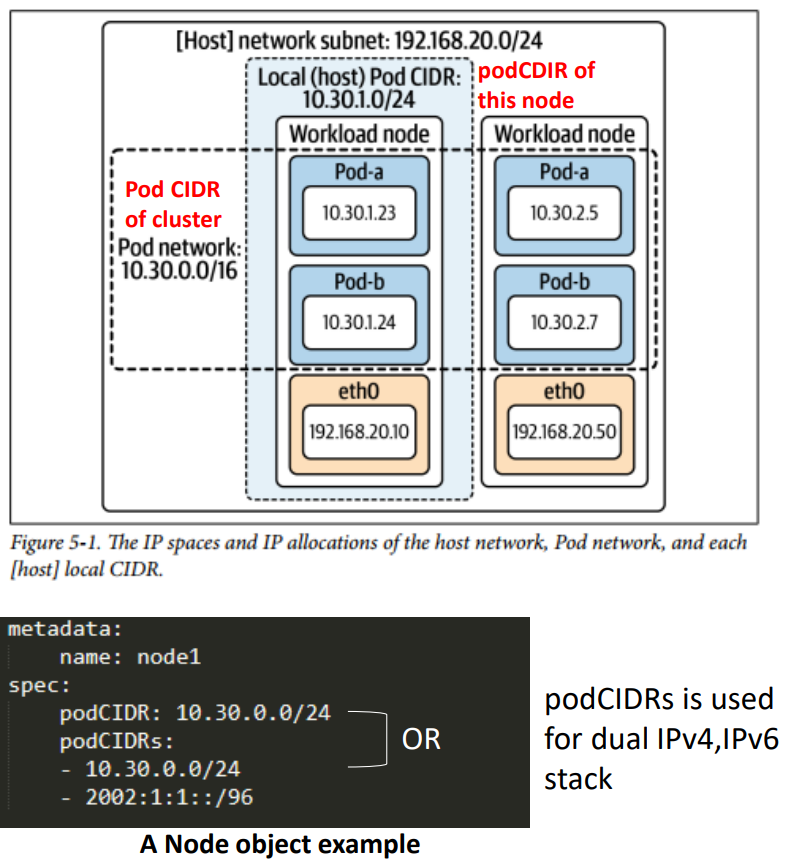
2. Routing Protocol: 파드의 IP 주소 간 트래픽이 올바르게 전달되도록 라우팅 경로를 전파
- 대표적으로 BGP가 사용되며, 이를 통해 호스트 커널의 라우팅 테이블이 업데이트됨
- BGP(Border Gateway Protocol)
- 일반적으로 사용되는 네트워크 프로토콜로 Calico에서 사용됨
- 커널 라우팅 테이블을 수정하여 각 잠재적 워크로드에 대한 경로를 포함함
- BGP(Border Gateway Protocol)
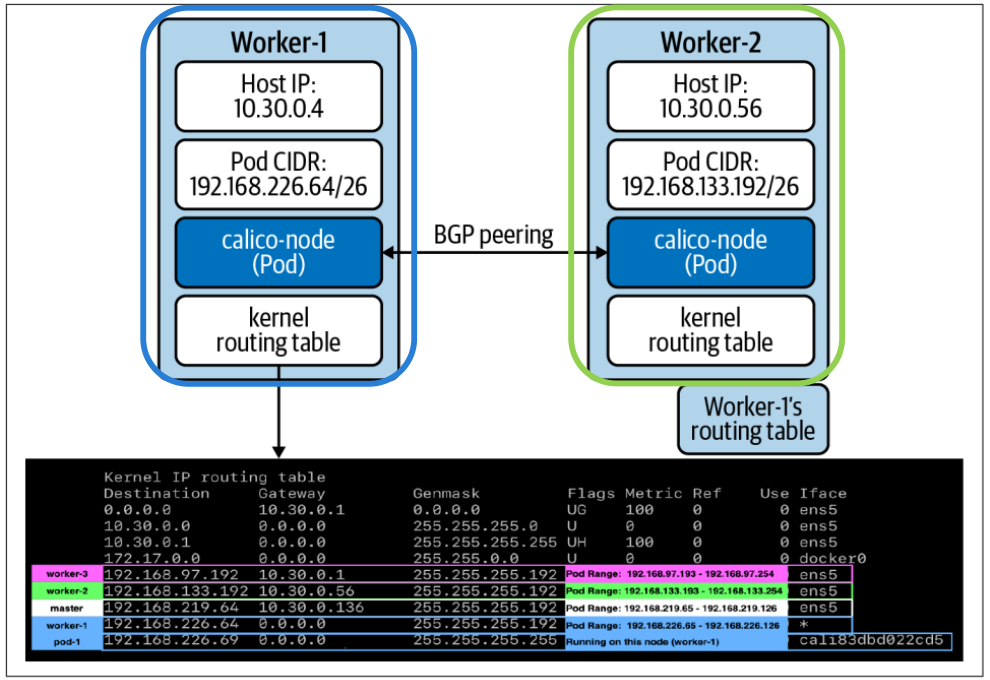
- 주의) IPAM example 사진과 CIDR IP가 다름
3. 캡슐화와 터널링 (Encapsulation and Tunneling)
- K8s 내부 네트워크와 실제 물리 네트워크를 분리하기 위한 기술
- 출발지/도착지 Pod IP가 적힌 패킷을 실제 호스트 노드의 IP 패킷으로 감싸서 전송하며, k8s CNI에서는 여러 프로토콜(VXLAN, Geneve, GRE) 중 VXLAN 프로토콜이 가장 널리 쓰임

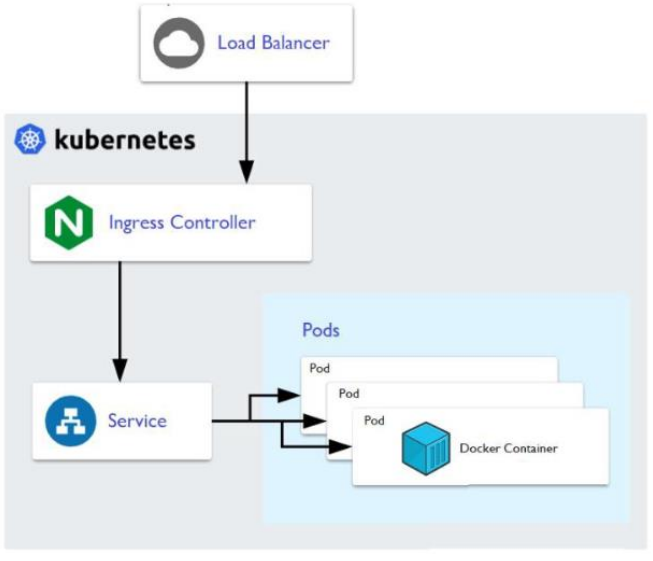
4. 워크로드 라우팅 (Workload Routability)
- 외부 클라이언트가 클러스터 내부망에 있는 Pod에 접근할 수 있게 해주는 Service Routing 메커니즘
- 주로 Ingress Controller나 Load Balancer를 통해 외부 트래픽을 받아 내부 Pod로 연결해 줌
5. 네트워크 정책 (Network Policy)
- Pod로 들어오거나(Ingress) 나가는(Egress) 트래픽의 허용 여부를 정의하는 방화벽 역할
- AWS의 인바운드/아웃바운드 규칙과 유사
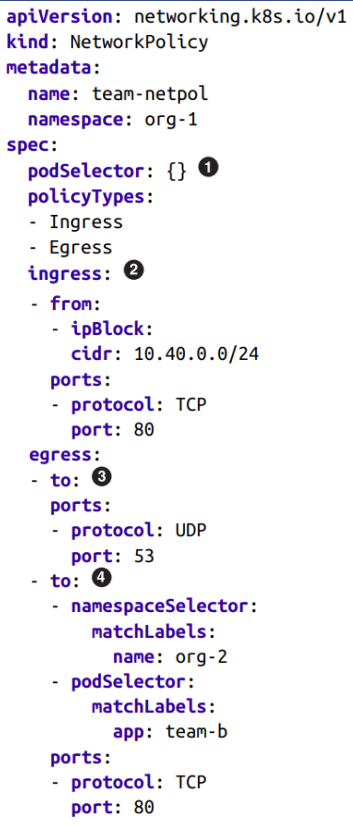
- podSelector: {} (적용 대상)
- 비어있는 것은 이 네임스페이스의 모든 Pod에 적용된다는 뜻
- ingress: (들어오는 트래픽 - Inbound)
- 정의된 IP 범위, protocol로 port에서 들어오는 트래픽 등을 허용
- egress: (나가는 트래픽 - Outbound)
- 정의된 namespace, label, protocol로 port의 워크로드로 전송되는 트래픽을 제한함
- 기본 k8s 방화벽은 너무 원시적이라, IP가 자주 바뀌는 외부 API 통신이나 복잡한 L7 제어나 거대한 클러스터 관리가 어려움
- Calico나 Cilium이 제공하는 독자적인 고급 NetworkPolicy 기능을 써야 함
- Complex condition evaluation (복잡한 조건 평가)
- 기본 K8s: "A 파드가 B 파드로 가는 것 허용"처럼 아주 단순한 AND 조건 정도만 가능
- CNI 고급 기능: 훨씬 복잡한 논리를 짤 수 있음
- ex) "A 파드이면서 동시에 B 라벨이 없고, 트래픽이 평일 업무 시간에만 발생할 경우 허용(OR, NOT 조건 등 활용)" 같은 세밀하고 복잡한 조건을 걸어 방화벽을 통제 가능
- Resolution of IPs based on DNS records (DNS 레코드 기반 IP 해석)
- 기본 K8s: 외부로 나가는 트래픽(Egress)을 제어할 때, 고정된 IP 주소(CIDR)로만 허용/차단 목록을 만들 수 있음
- (예: 142.250.190.46 접속 허용)
- CNI 고급 기능: IP 대신 도메인 이름(DNS)을 통과 조건으로 쓸 수 있음 (예: *.google.com 접속 허용)
- 외부 클라우드 서비스나 API들은 IP가 수시로 바뀌기 때문에, 실무에서는 IP를 직접 입력하는 대신 도메인 기반 정책이 반드시 필요함
- 기본 K8s: 외부로 나가는 트래픽(Egress)을 제어할 때, 고정된 IP 주소(CIDR)로만 허용/차단 목록을 만들 수 있음
- L7 rules (host, path, etc.) (L7 애플리케이션 계층 규칙)
- 기본 K8s: L3/L4 계층인 IP와 Port(예: TCP 80번 포트)만 보고 트래픽을 통제하기 때문에, 패킷 안에 무슨 데이터가 들었는지는 모름
- CNI 고급 기능: 패킷의 속을 까서 HTTP 통신(L7 계층)의 내용까지 보고 통제
- ex) 같은 웹 서버(TCP 80)로 가는 요청이더라도, GET /api/v1/users (조회)는 허용하지만 POST /api/v1/users (생성/수정)는 차단하는 식으로 훨씬 정교한 통제가 가능해짐
- Cluster-wide policy (클러스터 전역 정책)
- 기본 K8s: 네트워크 정책은 철저하게 네임스페이스(Namespace) 단위로만 갇혀 있음
- 만약 "모든 파드는 사내 보안망을 거쳐야 한다"라는 규칙을 만들려면, 클러스터에 네임스페이스가 100개 있으면 똑같은 정책 파일을 100번 복사해서 일일이 다 넣어줘야 함
- CNI 고급 기능: 'GlobalNetworkPolicy' 같은 기능을 제공하여, 클러스터 전체에 한 번만 딱 적용하면 모든 네임스페이스가 일괄적으로 따르도록 통제할 수 있어 관리자의 수고를 덜어줌
- 기본 K8s: 네트워크 정책은 철저하게 네임스페이스(Namespace) 단위로만 갇혀 있음
- Complex condition evaluation (복잡한 조건 평가)
CNI Plugin
- Pod 간 네트워크 통신을 담당하는 소프트웨어
- Cluster 안에 있는 어떤 Pod던지 간에 직접 통신을 할 수 있게끔 Pod에 주소를 주고, Routing table을 업데이트 해줌
'Cloud > Kubernetes' 카테고리의 다른 글
| [Cloud] K8s 요청 처리 단계, Service Account (0) | 2026.06.08 |
|---|---|
| [Cloud] Pod(Application) Update 종류 및 실습 (0) | 2026.06.03 |
| [Cloud] HPA (Horizontal Pod Autoscaling) (0) | 2026.06.03 |
| [Cloud] StatefulSet (0) | 2026.06.03 |
| [Cloud] Kubernetes Volumes III (Downward API, Job, CronJob, DaemonSet) (0) | 2026.05.08 |
'Cloud/Kubernetes' Related Articles
more



